AI Can Predict Product Recalls from Customer Reviews.
 Unsafe, mislabeled, and contaminated foods cause an estimated 76 million illnesses each year in the US, including 325,000 hospitalizations and 5,000 deaths. The Food and Drug Administration (FDA) can take months to identify and verify a problem before issuing a recall, so most recalls come from manufacturers, often after enough people have gotten sick to generate bad press.
Unsafe, mislabeled, and contaminated foods cause an estimated 76 million illnesses each year in the US, including 325,000 hospitalizations and 5,000 deaths. The Food and Drug Administration (FDA) can take months to identify and verify a problem before issuing a recall, so most recalls come from manufacturers, often after enough people have gotten sick to generate bad press.
But soon, artificial intelligence could comb through online reviews to identify serious threats to public health, and speed the process of a product recall, according to a new study co-authored by a School of Public Health researcher.
In the study, published in the Journal of the American Medical Informatics Association (JAMIA) Open, the researchers taught an AI to predict food product recalls from Amazon reviews with about 74-percent accuracy. The AI then used Amazon reviews to identify thousands of potentially unsafe food products that have not yet been investigated.
“Health departments in the US are already using data from Twitter, Yelp, and Google for monitoring foodborne illnesses,” says the study’s senior author, Elaine Nsoesie, assistant professor of global health. She explains that, in contrast, this study was able to look at the safety of specific food products. “Tools like ours can be effectively used by health departments or food product companies to identify consumer reviews of potentially unsafe products, and then use this information to decide whether further investigation is warranted.”
Nsoesie and her colleagues pulled 1,297,156 food product reviews from Amazon.com, matching 5,149 of the reviews to products that had been recalled by the FDA from 2012 to 2014.
Then they trained an existing “deep-learning” AI called Bidirectional Encoder Representation from Transformations (BERT) to interpret red flags in these customer reviews. BERT is trained on large bodies of English-language text such as English Wikipedia, and can interpret text for a given purpose.
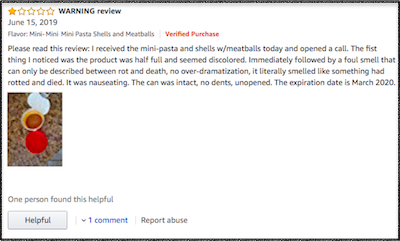
To train BERT to identify unsafe foods, they used crowdsourcing (by real humans) to categorize 6,000 of the reviews that contained words related to FDA recall reasons, such as “sick,” “label,” “ill,” “foul,” “rotten,” etc., along with metadata such as the review’s title and star rating. The crowdsourcing participants categorized the reviews in one of four ways: The consumer got sick or had an allergic reaction, or reported an error in the product’s label; the product seemed to have expired or looked/tasted foul and should be inspected; the review does not imply that the product was unsafe; or none of the above.
BERT was able to look at these same customer reviews and correctly identify recalled food products with 74-percent accuracy. It then found terms associated with FDA recalls in 20,000 other reviews, most of them for non-recalled products.
The study was co-authored by Kunlin Cai and Derry Wijaya of the Boston University Department of Computer Science, and Cynthia Vint, who was a Boston University student in the Computer and Information Systems program while working on the study. The study’s first author was Adyasha Maharana of the University of Washington, and the other co-authors were: Joseph Hellerstein, Valentina Staneva, and Miki Verma of the University of Washington; Yulin Hswen of Boston Children’s Hospital and the Harvard TH Chan School of Public Health; and Michael Munsell of Brandeis University.