
A Real-Time Change Detection Algorithm
BY GINA MANTICA
Robots navigate around a room thanks to cameras and algorithms that help them process images. But, as a robot starts moving around, so does the camera’s field of view. To control a robot’s movements and prevent it from crashing into objects, it needs to excel at change detection – or the process of finding differences between frames of a video when returning to the same location (e.g., a new box on the floor).

Artificial Intelligence Research Initiative affiliates Janusz Konrad and Prakash Ishwar, along with PhD student Ozan Tezcan, developed a supervised deep learning algorithm that automatically finds changes in a video even in complex scenarios that don’t exist in the dataset that the algorithm is trained on. The algorithm can be used as the first step in more complex computer vision and video processing tasks to allow real-time object classification and tracking. Their findings were recently published in IEEE Access.

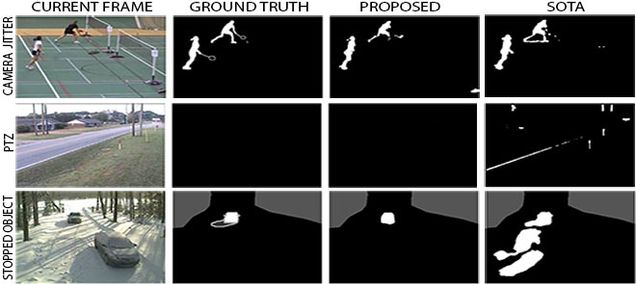
The ability of a computer to detect meaningful changes in a video happens through a process called background subtraction. “In Computer Science, background subtraction is an ancient and well-researched problem,” said Konrad. Early methods assumed a single background and “subtracted” it from the current video frame, but this approach works only in the simplest scenarios. In more complex videos, the backgrounds of videos are difficult to determine. For example, many background subtraction methods cannot determine accurately whether a car stopping on the road for several minutes or the leaves of trees swaying in the wind should be considered as part of the background.
To improve how well the algorithm detects changes in videos, Tezcan not only used many different types of video backgrounds to train the algorithm, but also multiple versions of the same background. Videos of highways, parks, offices, homes, and parking lots were altered to increase the amount of data used to train the algorithm. “We used a process called data augmentation, where we create new data from an existing dataset. We transformed videos to create pan effects, tilts, and zooms,” said Ishwar. The researchers also changed the lighting and chose videos taken in different weather conditions to diversify their dataset further. Training the algorithm on these “augmented backgrounds”, as Tezcan put it, is what makes their algorithm, BSUV-Net 2.0, unique and applicable to all sorts of videos.
Previous supervised background subtraction algorithms relied upon having access to at least some manually-annotated frames of the same video on which they were tested, rendering them impractical. But the BU team created a “plug and play” algorithm that can be used on unseen videos without requiring annotations. “The novelty of our algorithm is in the inputs and augmentations,” said Ishwar, “When we apply our algorithm to a variety of background-subtraction datasets used by researchers, it generalizes well.”

The algorithm’s performance and speed lend it to a variety of applications — from surveillance and law enforcement, to robots and smart technologies. “What was interesting is that Ozan modified the algorithm to run very fast, at video rates. There may be a use for this in real-time applications of the algorithm,” said Konrad.
For access to the open-source algorithm, click here.
Interested in learning more about the transformational science happening at the Hariri Institute? Sign up for our newsletter here.