Robot Reinforcement

A new machine-learning framework could be used to complete high-risk, complex tasks
By Liz Sheeley
Machine learning can identify potentially cancerous spots on mammograms or understand a spoken command to play music, but researchers don’t fully understand exactly how machine-learning algorithms, well, learn. That blind spot makes it difficult to apply the technique to complex, high-risk tasks such as autonomous driving, where safety is a concern.
In a step forward, a team of researchers led by Professor Calin Belta (ME, SE, ECE) has developed a new approach to teaching a robot, or a team of robots, a high-risk, complex task—a framework that could be applied to a host of tasks.
In a paper published in Science Robotics, the team demonstrated this framework with a proof-of-concept task by teaching two robots to cook, assemble and serve hot dogs together.
“This work is an attempt to bridge the gap between symbolic knowledge representation and reasoning with optimization-based planning while allowing the overall system to continuously and safely improve by interacting with its environment,” says doctoral fellow and first author of the paper Xiao Li (ME). “We hope that such an architecture can help us impart our knowledge and objectives to the robot, and improve our understanding of what it has learned, thus leading to more capable robotic systems.”
Their method combines techniques from machine learning and formal methods, an area of computer science that is typically used to guarantee safety, most notably used in avionics or cybersecurity software. These disparate techniques are difficult to combine mathematically and to put together into a language a robot will understand.
Belta and his team used a branch of machine learning known as reinforcement learning. When a computer completes a task correctly, it receives a reward that guides its learning process.
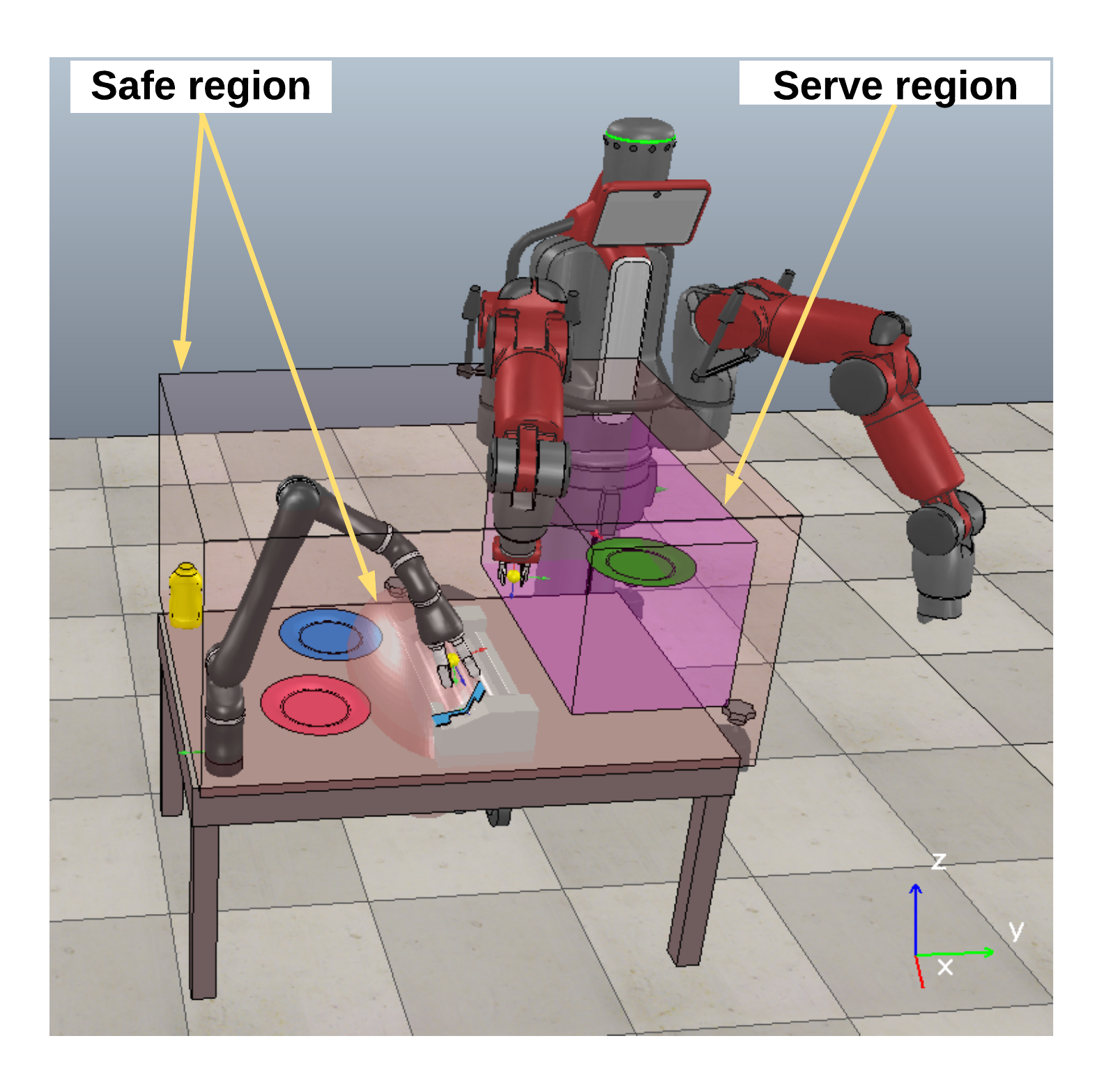
The researchers also built what’s known as prior knowledge into the algorithm. That information contains the steps the robots need to take to successfully cook the hot dogs, actions like pick up the hot dog and place it on the grill. That knowledge also included information that would be obvious to a human, but not to a robot – if the hot dog is already being held it doesn’t need to be picked up, for example.
Although the steps of the task are outlined in the algorithm, how exactly to perform those steps isn’t. When the robot gets better at performing a step, its reward increases, creating a feedback mechanism that pushes the robot to learning the best way to, for example, place a hot dog on a bun.
Integrating prior knowledge with reinforcement learning and formal methods is what makes this technique novel. By combining these three techniques, the team can cut down the amount of possibilities the robots have to run through to learn how to cook, assemble and serve a hot dog safely.
To test their theory that combining these three methods would be the most effective and safe way to teach these robots to cook hot dogs, they measured the success rate of each robot when it was trained with any combination of reinforcement learning and the other two techniques. The researchers were able to show that the highest success rate for both robots was when all three techniques were combined. Success here meant task completion while also remaining safe.
This type of framework allows the researchers to analyze the success rate of the stages of the task, unlike in other types of machine learning. That lets them understand and eliminate bottlenecks in the machine learning process—something that is extremely difficult to do.
Belta sees this work as a proof-of-concept demonstration of their general framework, and he hopes that moving forward that it can be applied to other complex tasks such as autonomous driving.