Privacy Preserving Smart-Room Analytics
Team: J. Dai, J.Wu, B. Saghafi, J. Konrad, P. Ishwar
Funding: This material is based on work supported by the US National Science Foundation under Smart Lighting ERC Cooperative Agreement No. EEC-0812056
Status: Ongoing (2014-…)
Summary: Although extensive research on action recognition has been carried out using standard video cameras, little work has explored recognition performance at extremely low temporal or spatial camera resolutions. Reliable action recognition in such a “degraded” environment would promote the development of privacy-preserving smart rooms that would facilitate intelligent interaction with its occupants while mitigating privacy concerns. This project aims to explore the trade-off between action recognition performance, number of cameras, and temporal and spatial resolution in a smart-room environment.

As it is impractical to build a physical platform to test every combination of camera positions and resolutions, we use a graphics engine (Unity3D) to simulate a room with various avatars animated using motions captured from real subjects with a Kinect v2 sensor.
We study the performance impact of spatial resolutions from a single pixel up to 10×10 pixels (an extremely low spatial resolution), the impact of temporal resolutions from 2 Hz up to 30 Hz and the impact of using up to 5 ceiling cameras.
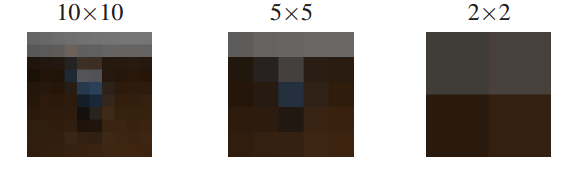
Results of this study indicate that reliable action recognition for smart-room centric gestures is possible in environments with extremely low temporal and spatial resolutions. An overview of these results is shown in the table below:

Additional resources on this project will be added soon.
For a more in-depth explanation of our methodology and the aforementioned results please refer to our paper below.
Publications:
- J. Dai, J. Wu, B. Saghafi, J. Konrad, and P. Ishwar, “Towards Privacy-Preserving Activity Recognition Using Extremely Low Temporal and Spatial Resolution Cameras,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Workshop on Analysis and Modeling of Faces and Gestures (AMFG), June. 2015.