Mobility and Activity Recognition in Smart Rooms
Humans spend most of their time indoors where they do a lot of different things. We hypothesize that by better understanding what they are doing we can tailor light and lighting to these activities to improve their task performance, to better meet their biological needs, and to improve their connectivity to electronic infrastructure. Identifying the position of objects, including humans, in indoor spaces can be achieved with a variety of modalities that includes the use of visible and infrared light, and with RF signals. An ideal approach would require the least infrastructure and would produce sufficient information to characterize activities yet would not result in apparent ‘photos’ of people. We seek to glean activities from the collected data, regardless of modality.
Thus the subsequent research focuses on developing machine-learning algorithms to understand user activity from low-dimensional user location data. As an outcome we expect to realize models and a framework to quantify relationships between location resolution and accuracy for smart room activity recognition that will apply to lighting-specific use cases.
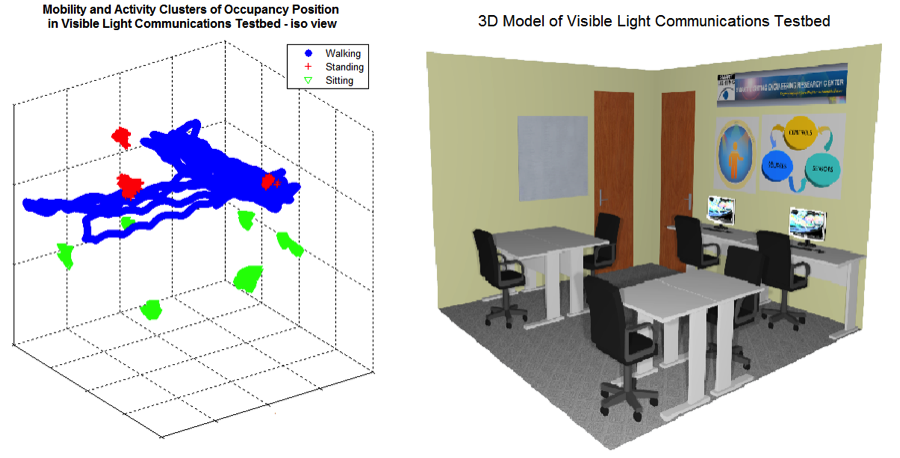
As an example, several illustrations are shown for an indoor space comprising our testbed. The points in Figure 1 (left) represent 3D location of occupants recorded by a high-resolution optical motion capture system. From the data, we applied a time series analysis to infer user motion as instantaneous and average velocities and , and processed a 5D feature vector . An unsupervised learning method clusters the data instances in the feature space to classes of activity, i.e., points clustered as “walking” are shown in blue, “standing” in red, and “sitting” in green. This clustering result is validated by the 3D layout model in Figure 1 (right). For each activity class, the 2D locations are grouped into regions in Figure 2 (left), again verified by the room layout in Figure 2 (right).
The unsupervised learning method used here does not require manual labeling of data nor prior layout information about the room – a significant advantage over other techniques. Thus the smart space is free to change for multiple functions. The algorithm can be implemented for online real-time adaptive activity recognition.
