Previous Projects
A Just-in-Time, Cross-Layer Instrumentation Framework for Diagnosing Performance Problems in Distributed Applications

Funding: NSF and Red Hat; Collaboration: Tufts University
Diagnosing performance problems in distributed applications is extremely challenging and time-consuming. A significant reason is that it is hard to know where to enable instrumentation a priori to help diagnose problems that may far occur in the future. In this work, we aim to create an instrumentation framework that automatically searches the space of possible instrumentation choices to enable the instrumentation needed to help diagnose a newly-observed problem. Our prototype, called Pythia, builds on workflow-centric tracing, which records the order and timing of how requests are processed within and among a distributed application’s nodes (i.e., records their workflows). Pythia uses the key insight that localizing the sources of high-performance variation within the workflows of requests that are expected to perform similarly gives insight into where additional instrumentation is needed.
AI for cloud Ops, in collaboration with Red Hat
Project link to VAIF: Variance-driven Automated Instrumentation Framework
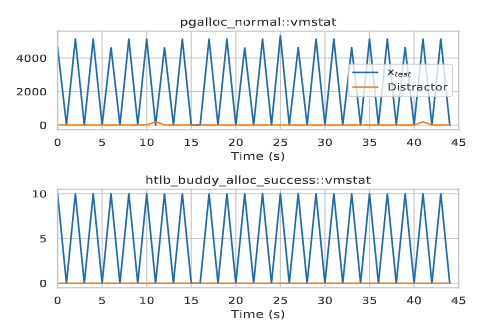
Scalable and Explainable Machine Learning Analytics for Understanding HPC Systems
Funding: Sandia National Laboratories
The goal of this project is to design scalable and explainable analytics methods to diagnose performance anomalies in high-performance computing (HPC) systems so as to help sustain the necessary performance and efficiency increases towards achieving exascale computing and beyond. Specific tasks include (1) Designing and building techniques for training a performance analysis framework and making sufficiently accurate predictions with less data; (2) investigating the integration of existing methods and the design of new methods to substantially improve explainability of the decision making the process of the performance analytics framework.
Architecting the COSMOS:A Combined System of Optical Phase Change Memory and Optical Links
Funding: NSF
Today’s data-intensive applications that use graph processing, machine learning or privacy-preserving paradigms demand memory sizes on the order of hundreds of GigaBytes and bandwidths on the order of TeraBytes per second. To support the ever-growing memory needs of the applications, Dynamic Random Access Memory (DRAM) systems have evolved over the decades. However, DRAM will not be able to support these large-capacity and -bandwidth demands in the future in an efficient and scalable way. While there is research on a number of alternate memory technologies (such as phase-change memory, magnetic memory, resistive memory, etc.), there is no clear winner among these technologies to replace DRAM. Moreover, none of these alternate memory technologies nor DRAM efficiently complements the silicon-photonic link technology that is expected to replace high-speed electrical links for processor-to-memory communication in the near future. This project aims to address the problems arising from limited memory capacity and bandwidth, which are significant limiting factors in application performance, through a unified network and memory system called COSMOS. COSMOS integrates Optically-controlled Phase Change Memory (OPCM) technology and silicon-photonic link technology to achieve a “one-stop-shop” solution that provides seamless high-bandwidth access from the processor to a high-density memory. The project goes beyond solely using OPCM as a DRAM replacement, and aims to demonstrate the true potential of OPCM as non-volatile memory and in processing-in-memory (PIM) design scenarios. At a broader level, the project seeks to improve the performance of many societal data-driven applications in various domains, including healthcare, scientific computing, transportation, and finance.
The research goals of this project are to design the first full system architecture for COSMOS, and then demonstrate its benefits using realistic application kernels, when OPCM is used as a DRAM replacement, in an OPCM+DRAM combination with persistence properties, and in OPCM as PIM scenarios. To achieve these ambitious goals, the project is organized into the following three research thrusts and a cross-cutting thrust. Thrust 1 designs a full-system architecture using OPCM and silicon-photonic links to address the memory capacity and bandwidth requirements of data-centric applications. Thrust 2 investigates the use of COSMOS for PIM, where the stored data is processed at the speed of light. Thrust 3 aims to create mechanisms and methods for application developers and the Operating System to profile and instrument applications for making effective use of COSMOS. The Cross-cutting Thrust builds a simulation methodology to accurately evaluate the benefits of OPCM as DRAM replacement as well as for combined OPCM+DRAM and OPCM as PIM designs.
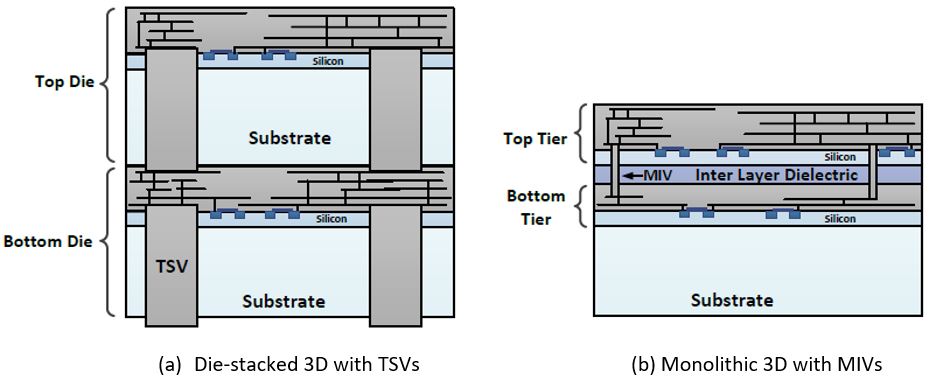
Managing Thermal Integrity in Monolithic 3D Integrated Systems
Funding: NSF; Collaboration: Stony Brook University and CEA-LETI, France
Integrated circuit (IC) research community has witnessed highly encouraging developments on reliably fabricating monolithic three-dimensional (Mono3D) chips. Unlike through silicon via (TSV) based vertical integration where multiple wafers are thinned, aligned, and bonded; in Mono3D ICs, multiple device tiers are formed on a single substrate following a sequential fabrication process. Vertical interconnects, referred to as monolithic inter-tier vias (MIVs), are orders of magnitude smaller than TSVs (nanometers vs. micrometers), enabling unprecedented integration density with superior power and performance characteristics. The importance of this fine-grained connectivity is emphasized particularly because modern transistors have reached sub 10 nm dimensions. Despite the growing interest in various aspects of Mono3D technology, a reliable framework for ensuring thermal integrity in dense Mono3D systems does not yet exist. This research fills this gap with its primary emphasis on leveraging Mono3D-specific characteristics during both efficient thermal analysis and temperature optimization. Our objective is to facilitate future progress on both design and fabrication aspects of Mono3D technology by developing a comprehensive framework for managing thermal issues. The results of this research will provide a better understanding of unique thermal characteristics in Mono3D ICs and help mitigate these thermal issues through efficient analysis and optimization.
Modeling the Next-Generation Hybrid Cooling Systems for High-Performance Processors

Funding: NSF; Collaboration: MIT and Brown University
Design of future high-performance chips is hindered by severe temperature challenges. This is because existing cooling mechanisms are not equipped to efficiently cool power densities reaching hundreds to several thousand watts per centimeter square, which are expected in exascale systems. There are several highly-efficient emerging cooling technologies that are being developed by thermomechanical engineers; however, these technologies are not easily accessible for experimentation to computer engineers for co-designing and optimizing their aggressive processor architectures together with the cooling subsystem. To close this gap, this project proposes to develop a software infrastructure that enables accurate modeling of cutting-edge cooling methods and, further, facilitates mutually customizing the computing and cooling systems to dramatically push beyond the system performance per watt that is achievable in today’s systems. Specific tasks include: (1) synthesizing novel physical device-level models into compact representations, (2) using measurements on prototypes and detailed simulators for validation of the proposed models, and (3) developing the necessary automation tooling to provide the ability for design and optimization of hybrid customized cooling subsystems together with a given target computing system.
Github Link
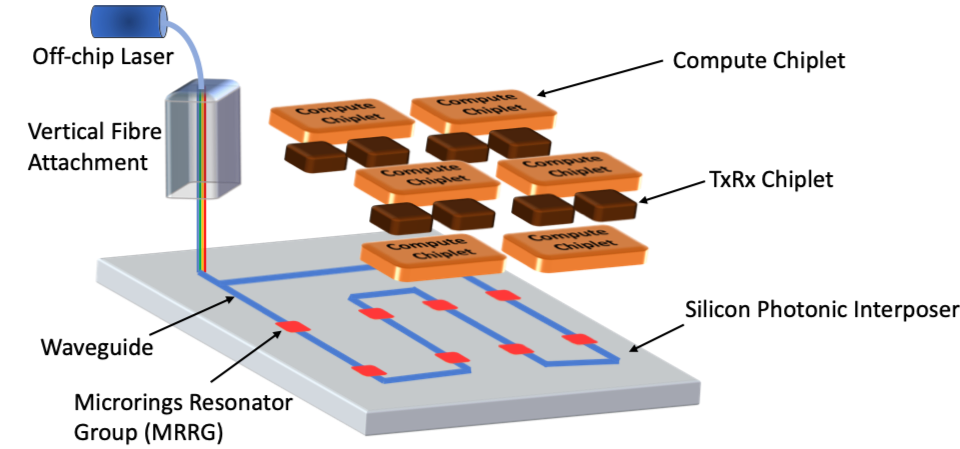
Reclaiming Dark Silicon via 2.5D Integrated Systems with Silicon-Photonic Networks
Funding: NSF; Collaboration: CEA-LETI, France
The design of today’s leading-edge systems is fraught with power, thermal, variability and reliability challenges. As a society, we are increasingly relying on a variety of rapidly evolving computing domains, such as cloud, internet-of-things, and high-performance computing. The applications in these domains exhibit significant diversity and require an increasing number of threads and much larger data transfers compared to applications of the past. Moreover, power and thermal constraints limits the number of transistors that can be used simultaneously, which has lead to the Dark Silicon problem. To handle the needs of the next-generation applications, there is a need to explore novel design and management approaches to be able to operate the computing nodes close to their peak capacity. This project uses 2.5D integration technology with silicon photonic networks to build heterogeneous computing systems that can provide the desired parallelism, heterogeneity, and the network bandwidth to handle the demands of the next-generation applications. To this end, we investigate the complex cross-layer interactions among devices, architecture, applications, and their power/thermal characteristics and design a systematic framework to accurately evaluate and harness the true potential of the 2.5D integration technology with silicon-photonic networks. Specific research tasks focus on cross-layer design automation tools and methods, including pathfinding enablement, for the design and management of the 2.5D integrated system with silicon-photonic networks.
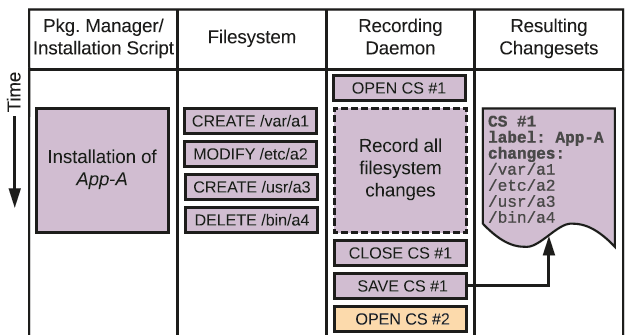
Scalable Software and System Analytics for a Secure and Resilient Cloud
Funding: IBM Research
Today’s Continuous Integration/Continuous Development (CI/CD) trends encourage rapid design of software using a wide range of customized, off-the-shelf, and legacy software components, followed by frequent updates that are immediately deployed on the cloud. Altogether, this component diversity and break-neck pace of development amplify the difficulty in identifying, localizing, or fixing problems related to performance, resilience, and security. Furthermore, existing approaches that rely on human experts have limited applicability to modern CI/CD processes, as they are fragile, costly, and often not scalable.
This project aims to address the gap in effective cloud management and operations with a concerted, systematic approach to building and integrating AI-driven software analytics into production systems. We aim to provide a rich selection of heavily-automated “ops” functionality as well as intuitive, easily-accessible analytics to users, developers, and administrators. In this way, our longer-term aim is to improve performance, resilience, and security without incurring high operation costs.
3D Stacked Systems for Energy‐Efficient Computing: Innovative Strategies in Modeling and Runtime Management

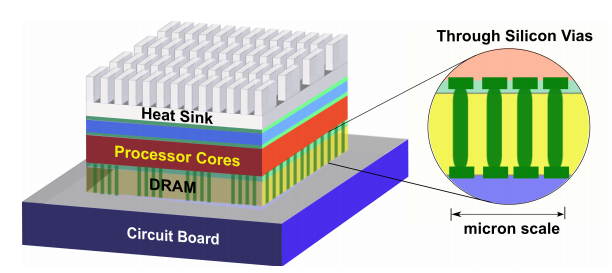
Funding: NSF CAREER and DAC Richard Newton Graduate Student Scholarship
3D stacking is an attractive method for designing high-performance chips as it provides high transistor integration densities, improves manufacturing yield due to smaller chip area, reduces wire-length and capacitance, and enables heterogeneous integration of different technologies on the same chip. 3D stacking, however, comes with several key challenges such as higher on-chip temperatures and lack of mature design and evaluation tools.
This project focuses on several key aspects that will enable cost-efficient design of future high-performance 3D stacks: (1) Thermal modeling and management of 3D systems; (2) Novel cooling (e.g., microchannel based liquid cooling, phase-change materials, etc.) modeling and control to improve cooling efficiency; (3) Architecture-level performance evaluation and optimization of 3D design strategies to maximize performance and energy efficiency of real-life applications; (4) Exploration of heterogeneous integration opportunities such as stacking processors with DRAM layers or with Silicon-Photonics network layers.
Energy-Efficient Mobile Computing

Mobile devices handle diverse workloads ranging from simple daily tasks (i.e., text messaging, e-mail) to complex graphics and media processing while operating under limited battery capacities. Growing computational power and heat densities in modern mobile devices also pose thermal challenges (i.e., elevated chip, battery, and skin temperatures) and lead to undesired performance fluctuations due to insufficient cooling capabilities, and as a result, frequent throttling. Designing practical management solutions is challenged by the diversity in computational needs of different software programs and also by the added complexity in the hardware architecture (i.e., specialized accelerators, heterogeneous CPUs etc.). Addressing these concerns requires revisiting existing management techniques in mobile devices to improve both thermal and energy efficiency without sacrificing user experience.
Our research in addressing energy and thermal efficiency of mobile devices focuses on (1) designing lightweight online frameworks for monitoring the energy/thermal status and for assessing performance sensitivity of applications to hardware and software tunables; (2) practical runtime management strategies to minimize energy consumption and mitigate thermally induced performance losses while providing sufficient user experience; (3) generating software tools and workload sets for enabling evaluation of emerging mobile workloads under realistic usage profiles.
Managing Server Energy Efficiency

The diversity of the elements contributing to computing energy efficiency (i.e., CPUs, memories, cooling units, software application properties, availability of operating system controls and virtualization, etc.) requires system-level assessment and optimization. Our work on managing server energy efficiency focuses on designing: (1) necessary sensing and actuation mechanisms such that a server node can operate at a desired dynamic power level (e.g., power capping), (2) resource management techniques on native and virtualized systems such that several software applications can efficiently share available resources, (3) cooling control mechanisms that are aware of the inter-dependence of performance, power, temperature-dependent leakage power, and cooling power.
Simulation and Management of HPC Systems

Additional levels of management and planning decisions take place at the data center level. These decisions, such as job allocation across the computing nodes, impact energy consumption and performance. HPC applications, e.g., scientific computing loads, typically occupy many server nodes, run for a long time, and include heavy data exchange and communication among the threads of the application.
Our work in this domain focuses on optimizing the cooling energy of the data center and the performance of HPC applications simultaneously. This work includes developing simulation methods that can accurately estimate power and performance of realistic workloads running on large-scale systems with hundreds or thousands of nodes. We also design strategies to assess and optimize system resilience.