Current Projects
Research on Large-Scale Computing Systems Analytics and Optimization
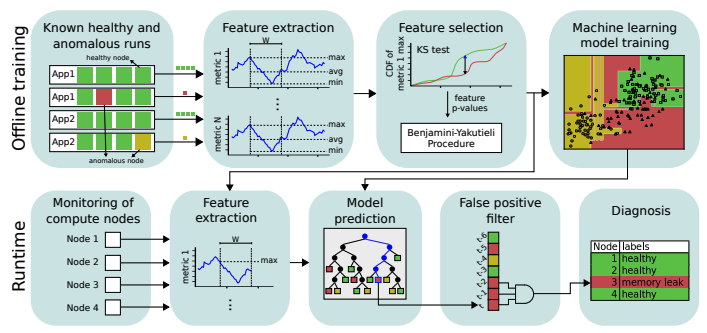 |
Automated Analytics for Improving Efficiency, Safety, and Security of HPC SystemsFunding: Sandia National LaboratoriesPerformance variations are becoming more prominent with new generations of large-scale HPC systems. Understanding these variations and developing resilience to anomalous performance behavior are critical challenges for reaching extreme-scale computing. To help address these challenges, there is increasing interest in designing automated data analytics methods that can make sense of the diverse telemetry collected from CPUs, GPUs, and job schedulers. Existing methods, however, rely heavily on manual analysis and are often tailored to a specific type of application, system, or anomaly. |
 |
LLM-Based Tracing Management for User-Friendly Performance Analysis in the CloudFunding: GoogleModern service-oriented software systems are distributed systems with microservice architectures involving deeply nested remote procedure calls (RPCs). State-of-the-art tracing tools collect a huge amount of tracing data from these calls to monitor system health and sanity check day-to-day operations. Querying and analyzing this data is a substantial challenge for experts, let alone new users. This project aims to create a system that leverages recent advances in natural language |
Research on Designing Future Energy-Efficient Computing Systems
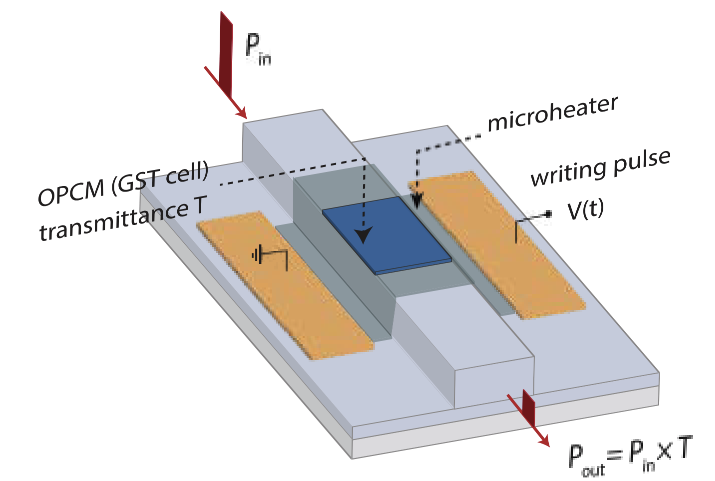 |
Optically-Controlled Phase-Change Memory: Toward Scalable Acceleration of Neural and Language ModelsFunding: NSFThe expansion of large-scale AI models has brought to light the inherent limitations of traditional electronic accelerators. With the breakdown of Dennard’s scaling, these accelerators face a fundamental constraint. As transistor density increases, so does power consumption, leading to thermal and energy-efficiency bottlenecks that lead to diminishing performance gain. While electronic processing-in-memory (PIM) architectures have been proposed to mitigate the cost of data movement by colocating storage and computation, they are not immune to the same fundamental scaling laws that affect conventional electronics, still being constrained by the physical limits of parallelism and the significant energy overheads associated with repeated multiply–accumulate (MAC) operations. Optical phase-change material (OPCM) crossbars offer a compelling alternative, as they store data directly within the programmable transmission state of each OPCM device, thereby embedding matrix–vector multiplication directly within the physics of light propagation. In this process, inputs are encoded into optical amplitudes, the multiplication is performed as light passes through the OPCM devices, and additions occur naturally through optical interference along shared waveguides. This enables highly parallel MAC execution with reduced latency and orders-of-magnitude lower energy consumption compared to CMOS-only designs. Beyond supporting the linear algebra kernels that dominate neural networks and large language models, OPCM arrays can also be reconfigured for combinatorial optimization tasks, as demonstrated in photonic Ising machines. By combining photonic compute fabrics with CMOS peripheral logic for nonlinear functions, quantization, and system control, this project explores a hybrid architecture that overcomes electronic scaling bottlenecks and establishes OPCM accelerators as a scalable, energy-efficient substrate for next-generation AI and scientific computing.
|
 |
FlexDC: Flexible Artificial Intelligence Data Centers for Optimized ComputingFunding: NSFElectricity consumption of data centers poses significant risks to both environmental sustainability and power grid stability. To meet the increasing power demand, there is a pressing need to expand the grid’s power generation capacity. However, adding new power and expanding transmission are both costly and take typically longer than the pace data centers are built. Grid is already strained in many states, with data centers constituting 10-25% of the entire state’s electricity consumption in Iowa, Nebraska, North Dakota, Oregon, and Virginia. The vast majority of current electricity production comes from fossil fuels, which is long-term unsustainable and has a tremendous carbon footprint. Wouldn’t it be appealing if data centers, whose growth is contributing to the rapidly increasing electricity demand, could emerge as a major enabler of expanding electricity generation from renewables? This would effectively make the growth of the IT sector sustainable and environmentally neutral, if not beneficial. This project aims at developing a framework for making such a vision the reality, particularly through integrating AI data centers into emerging smart grid and green energy programs. |
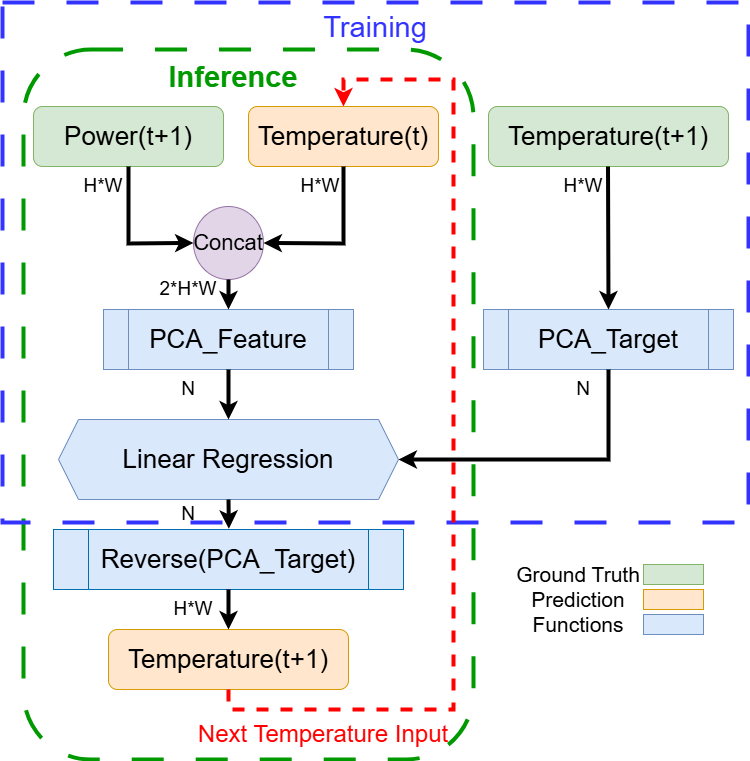 |
Fast ML‑Enhanced Compact Thermal Modeling for 3D ICsFunding: NSFWith growing transistor densities, analyzing temperature in 2D and 3D integrated circuits (ICs) is becoming more complicated and critical. Finite-element solvers give accurate results, but a single transient run can take hours or even days. Compact thermal models (CTMs) shorten the temperature simulation running time using a numerical solver based on the duality between thermal and electric properties. However, CTM solvers often still take hours for small-scale chips because of iterative numerical solvers. Recent work has explored machine learning (ML) models for temperature prediction, but these approaches typically require massive training datasets and long GPU runtimes to converge. Our goal is to bypass that barrier. In this project we plan to design a lightweight ML framework that integrates directly with PACT (our previously build CTM) to accelerate both steady-state and transient thermal simulations without relying on large-scale data. The core idea is to combine principal component analysis (PCA) with a closed-form linear regression model that predicts temperature from power traces. Since the regression weights are computed analytically, training is reduced to minutes, even for complex 3D architectures. |
 |
Sustainable IT and IT for SustainabilityFunding: BU College of Engineering Dean’s Catalyst AwardThe computing ecosystem continues to grow at a breakneck pace and consumes a substantial portion of the world’s electricity. Currently, the vast majority of electricity production comes from fossil fuels, which is long-term unsustainable and has a tremendous environmental impact. There is a growing motivation to integrate renewables; however, volatility of renewables creates new challenges for the power grid operators, who need to dynamically balance electricity supply and demand. Wouldn’t it be appealing if computing, whose growth is contributing to increased electricity demand, could emerge as a major enabler of increased electricity generation from renewables? This would also make the growth of the computing systems sustainable. This proposal aims at developing a framework for making such a vision the reality, particularly through integrating large data centers (HPC clusters, grid engines, or other data centers) into emerging smart grid programs. We propose to develop a collaborative and distributed control framework for the computing sector that helps stabilize the grid, while providing power cost incentives for data centers. Specifically, this project seeks to build computing demand response control opportunities, where computing systems follow power provider requests when regulating their power consumption, to improve the nation’s power supply efficiency and robustness, simultaneously with improving sustainability of computing.
|