Overview
Data is stored in cloud storage services such as AWS S3 buckets, Google Drive, or One Drive. Alternatively, data may also be made available via Application Programming Interface (API) by the organization hosting the data. Accessing these sources require an internet connection and often an application to interact with the remote servers hosting the data.
A dedicated node, called the Data Transfer Node, is available on the SCC for these types of data transfer tasks. The Data Transfer Node has its own high bandwidth internet connection and its only intended to be used for data transfer tasks. This page contains the following sections:
- The Data Transfer Node
- Submitting a Batch Job
- Using SCC OnDemand for Interactive Data Transfer
- Suggested Software and Modules for Transferring Data from Cloud Storage
The Data Transfer Node
The data transfer node is a single server named “scc-globus.bu.edu” that provides a direct 10GbE connection from the SCC to the internet for data transfer. The data transfer node is intended only for data transfer tasks and not for compute-intensive workloads. In comparison, the SCC compute nodes offer large computing capacity, but reside on a private network and share a connection to the outside world which limits the data transfer speeds. The data transfer node can be requested with the “-l download” command line option with a maximum runtime of 24 hours and limited to a single processor core.
Submitting a Batch Job
The -l download command line option for qsub will place your job on the data transfer node. This can be done for standard qsub batch job submissions either on the command line or inside of a batch script.
Example qsub command line:
scc1$ qsub –P projectname -l download download.qsubExample batch script:
This example script would use the data transfer node to synchronize files from Amazon Web Services S3 Service. A researcher should change the module and commands for their own purposes.
#!/bin/bash -l
#$ -P projectname
#$ -l download
module load awscli
aws s3 sync s3://mybucket scc-directoryNote that the data transfer node does not accept interactive jobs from the scheduler; neither qsh nor qrsh requests will work with the -l download command line option. For interactive use, researchers can SSH directly to scc-globus.bu.edu from within the cluster or use SCC OnDemand. The scc-globus node is dedicated to file transfers and interactive usage through SSH is subject to the same policies as apply on the login nodes.
Using SCC OnDemand for Interactive Data Transfer
Some data transfer programs must be run interactively, such as using the Firefox browser to access Google Drive cloud storage. For these applications, we recommend using a Desktop session on SCC OnDemand for a remote desktop on the data transfer node. This can be done by selecting a “Desktop” interactive app, adding the “-l download” option to the “Extra Qsub Options” field and launching the job.
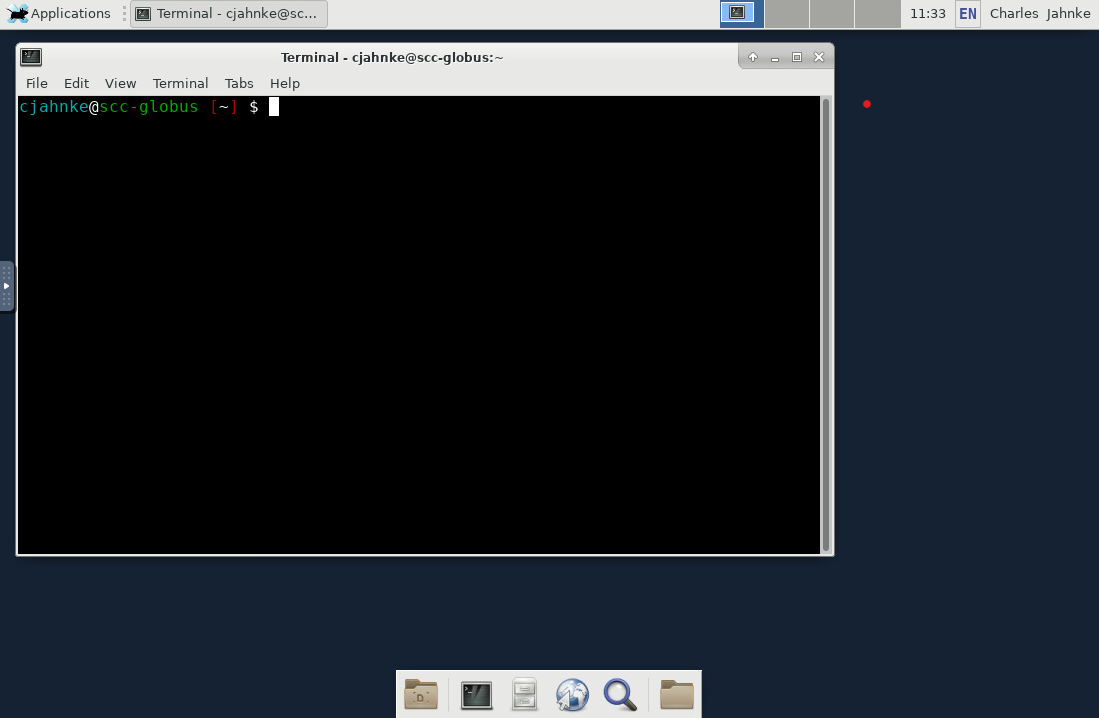
Once the job starts, you can connect to the desktop session and find yourself on the scc-globus.bu.edu node with the ability to open web browsers or launch interactive download applications.
Suggested Software and Modules for Transferring Data from Cloud Storage
There are many third party applications available that try to make transferring data from a cloud service provider easier by automating the task with only a few lines of commands. It is common for these tools to require upfront configuration to setup authentication in order to connect to a cloud service and access the data. Although we suggest these modules for your use, we do not guarantee they will work in all scenarios.
lftp
lftp is a command line program that can transfer files from remote servers using FTP, SFTP, HTTP, and several other protocols. It is available as a system utility and does not require and modules to be loaded. lftp has a wide array of commands that can be used and its website has tutorials and documentation. Here is an example of using lftp to transfer an entire directory from a remote FTP server:
lftp -u username ftp.someserver.org/path/to/remote/directory -e "cd path/to/scc/destination ; mirror; exit"
You will be prompted for the password on the remote server. This will copy the specified directory on the remote server to the destination you specify on the SCC.
Rclone
Rclone is a command line program that allows one to configure a connection to over 40 cloud storage products. Use the following module load command to load rclone:
scc1$ module load rcloneAfter loading the module, rclone needs to be configured to communicate with the cloud provider of your choice. Below are links to instructions on how to configure rclone with common cloud providers. Click on the link for the cloud provider you are connecting to and follow the instructions.
The list of all supported providers are available on rclone’s homepage.
Rclone: Using the OnDemand Files App
After you’ve configured your cloud account with rclone, a file containing your authenticated clouds will be saved in your home folder: ~/.config/rclone/rclone.conf. OnDemand will automatically detect any entries in this file and will appear in your Files menu as shown below [1].
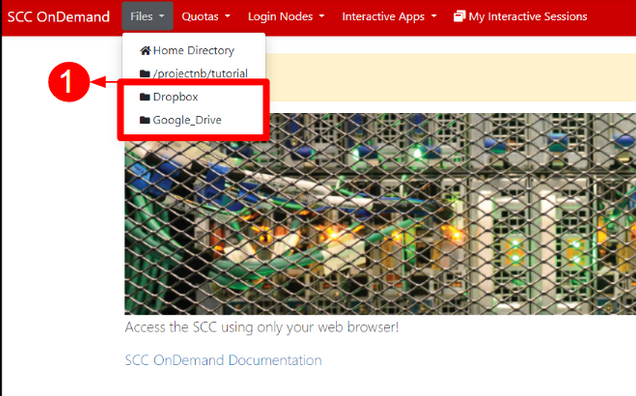
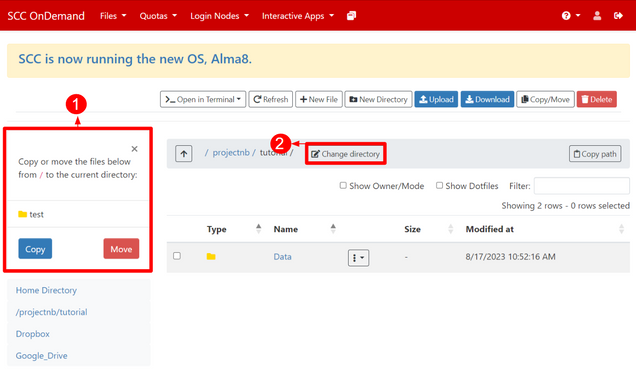
You can move or copy files between your cloud account and the SCC using the built in functionality highlighted below. Navigate to the source path to your files, check the box of the file to be transferred [1], and select Copy/Move [2].
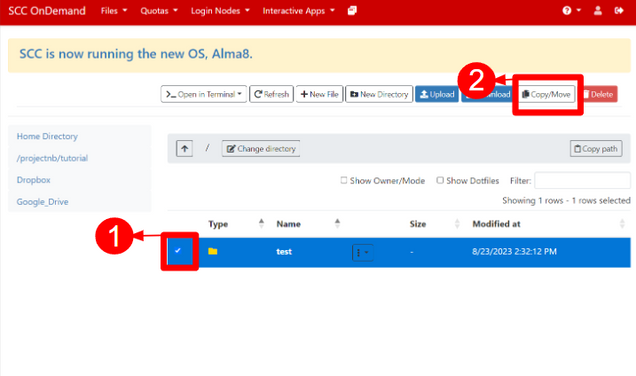
A menu will appear on the left dashboard with the option to Copy or Move [1]. You must change to the target directory which you can manually enter by selecting the Change directory [2] option or by selecting your project space on the left. When you have changed to the correct target directory, select your transfer option [1]. Note: Move will remove a copy of the file from the source.
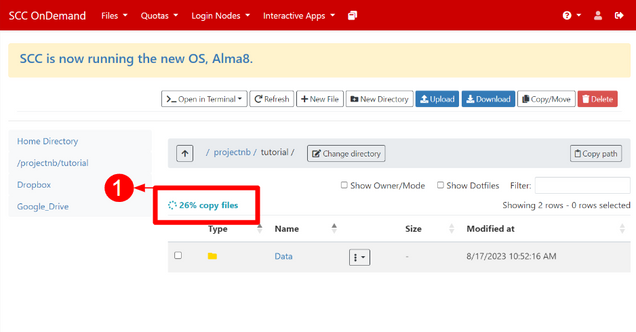
Your transfer will then initiate which initiate and you can track with the in-page status [1].
AWSCLI
AWS Command Line Interface (AWSCLI) is a command line program used to manage AWS services, but also can be used to transfer data from/to AWS S3 buckets. Use the following module command to load awscli:
scc1$ module load awscliIf you are connecting to a secured S3 bucket, you will need to configure awscli with authentication information in order to gain access to the data. For a basic configuration setup, run “aws configure” command. This will ask you to enter the “AWS Access Key ID”, the “AWS Secret Access Key”, and “Default region name”. The administrator of your AWS account can help you find this information.
After the configuration is complete, you will use the “aws s3“ groups of commands to interact with an SCC bucket. For example, to synchronize the AWS S3 bucket with a local directory, one may run the following command:
scc1$ aws s3 sync s3://mybucket scc-directoryThe following are links to help pages for commands that maybe helpful for exploring and transferring data from an S3 bucket:
Click here to access the documentation of all “s3” commands available.