Description
R is a language and environment for statistical computing and graphics. R provides a wide variety of statistical and graphical techniques and is highly extensible. Example analysis that can be done with R include linear and nonlinear modeling, classical statistical tests, time-series analysis, classification, and clustering.
Availability
R is free software under the GNU project and is available for Windows, macOS, and Linux systems. To install R on your local system, visit the R Project website to download the installation files.
On the SCC there are multiple versions of R available as modules. A complete list of R versions available can be found on the R modules summary page. One can also view this list inside a terminal connected to the SCC by executing the following command:
scc1$ module spider RQuick Start Guide to using R on the SCC
Below are two quick start guides for using R on the SCC and the third bullet point is a link to a video for a more detailed introduction to using R on the SCC.
- Using OnDemand
- Starting R Console Within a Terminal
- “Introduction to Using R and RStudio on the SCC” (video)
Using OnDemand
- Log on to the SCC OnDemand Portal. (See our OnDemand page to learn more about this portal).
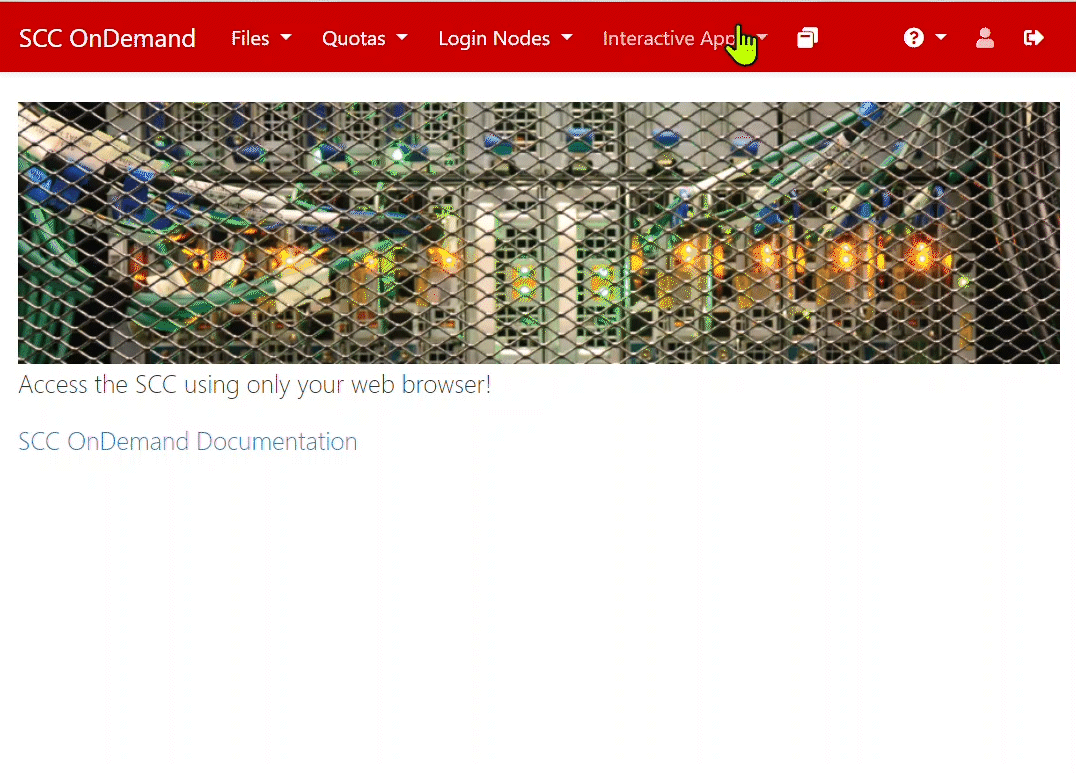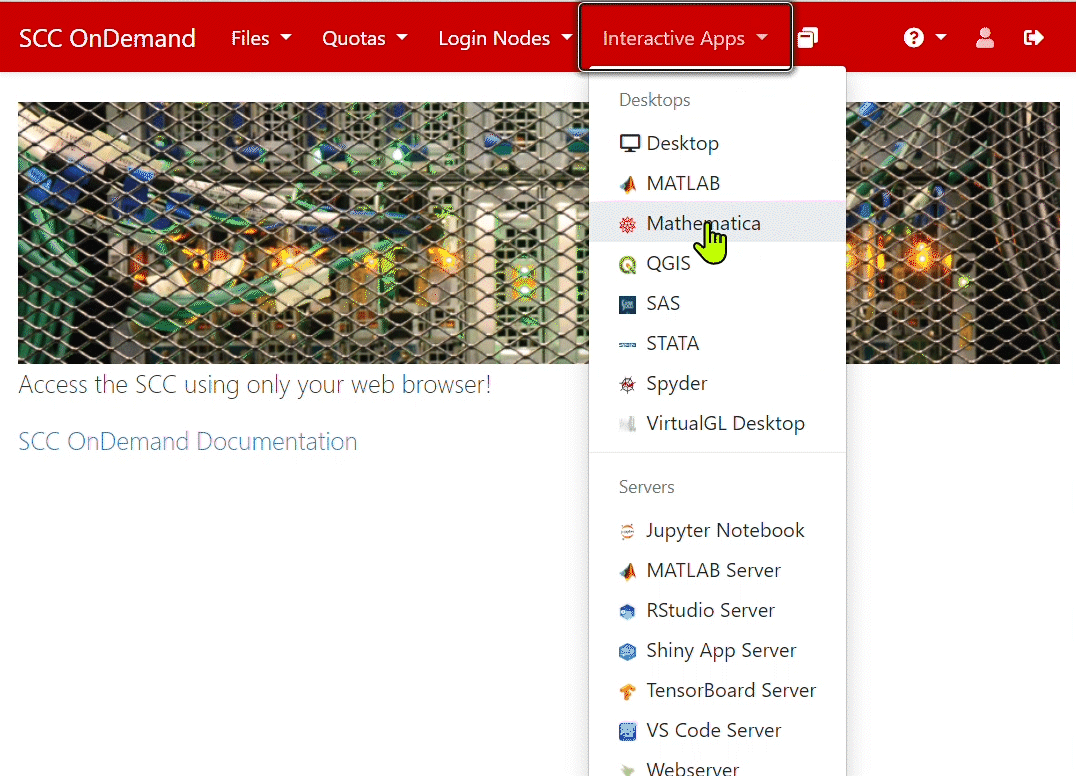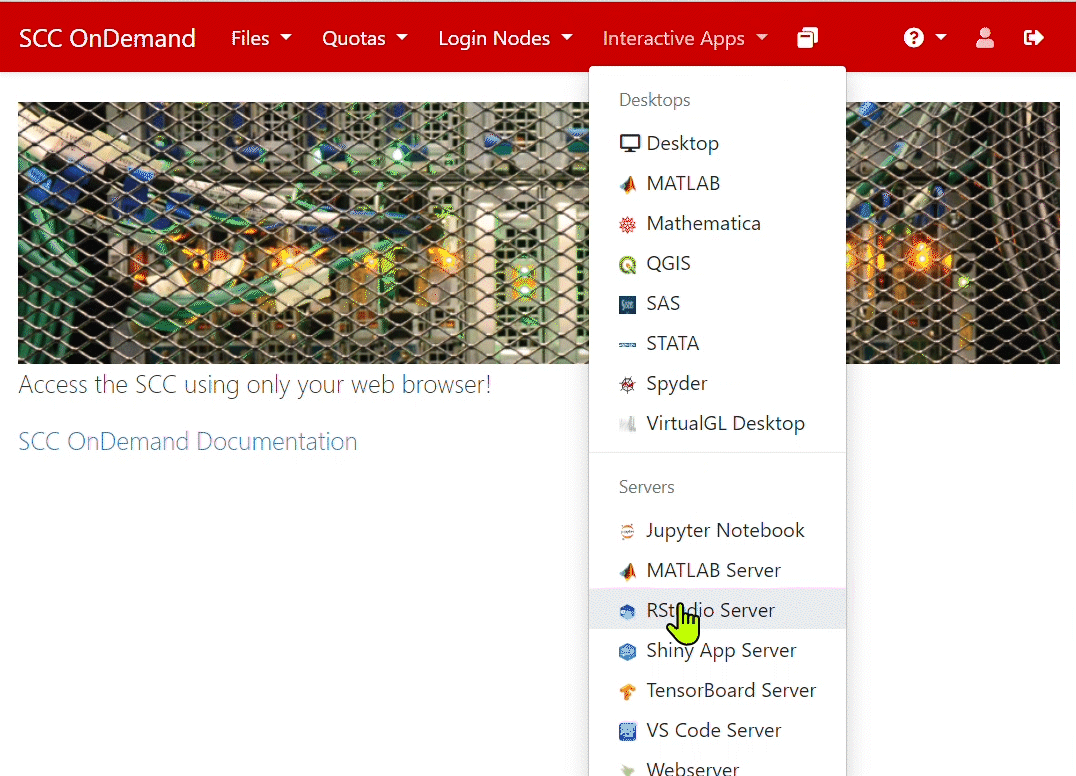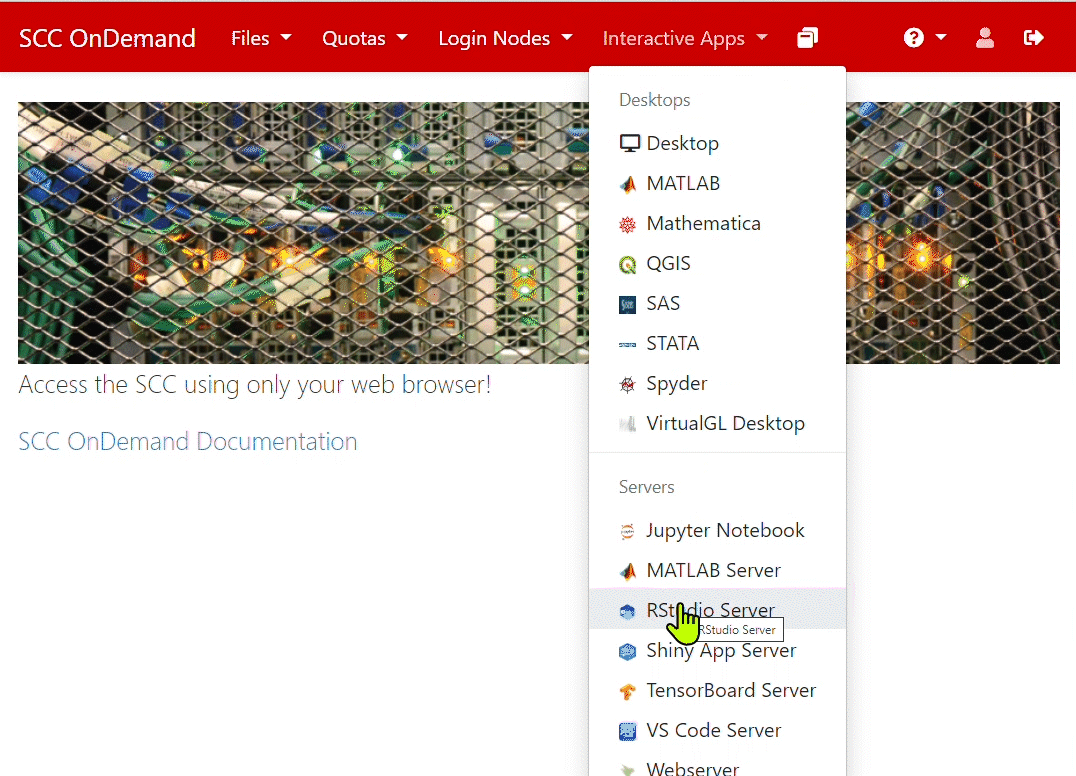
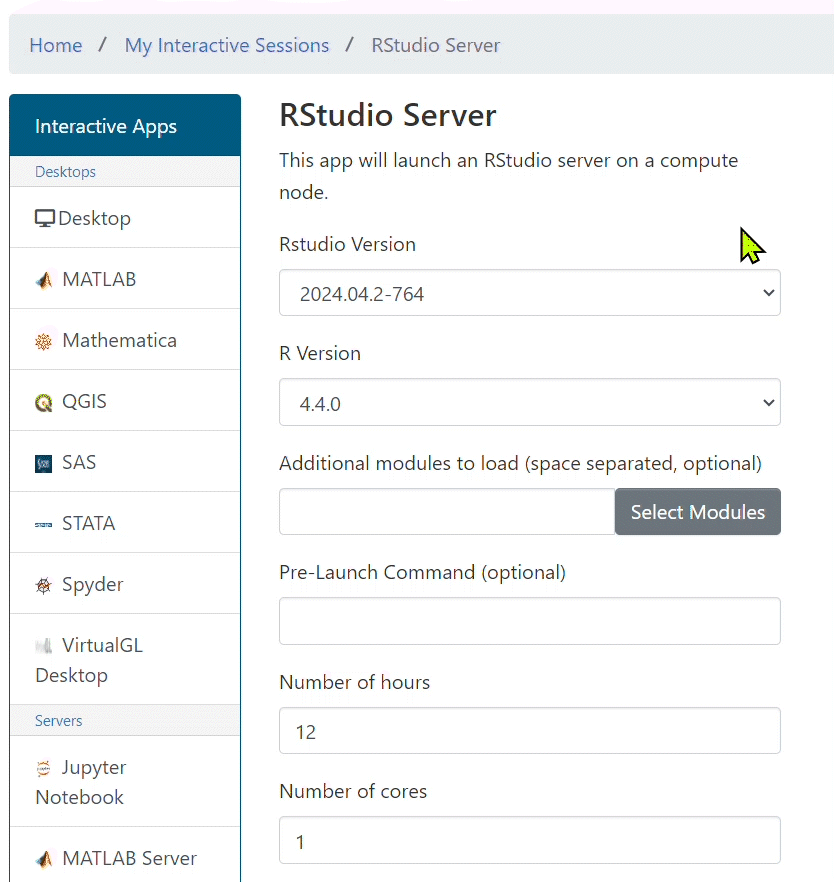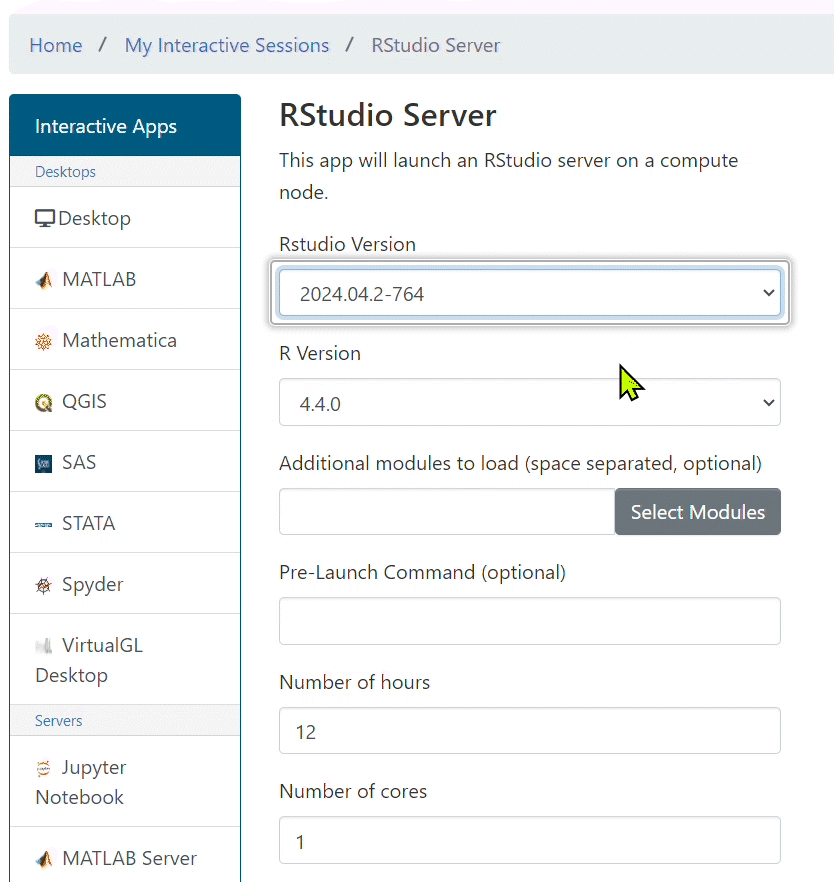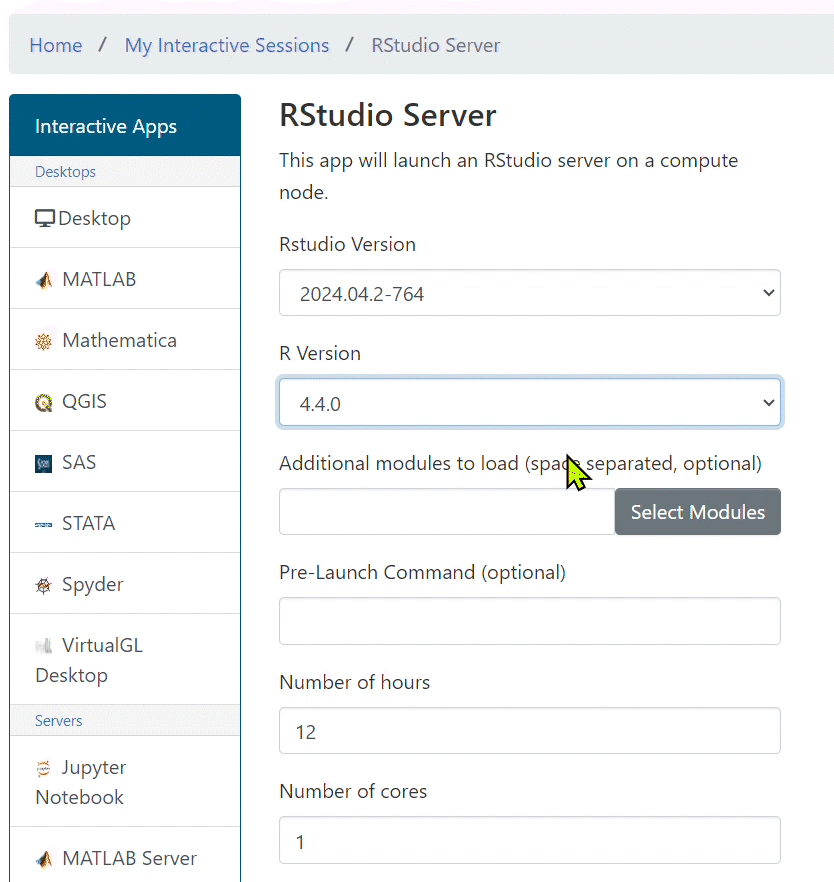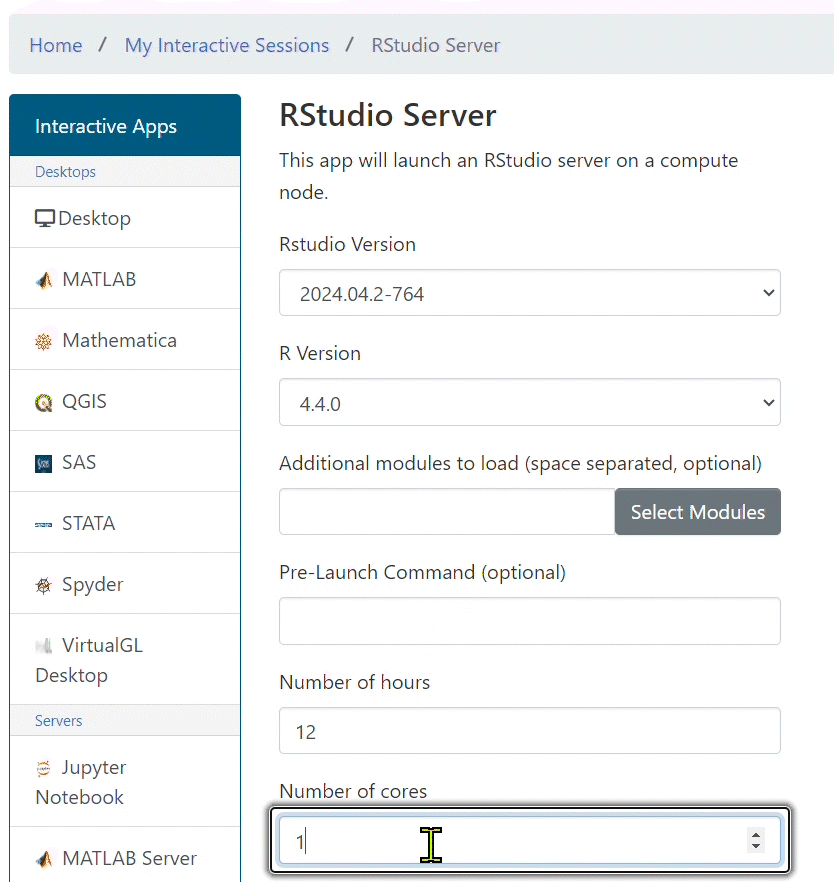
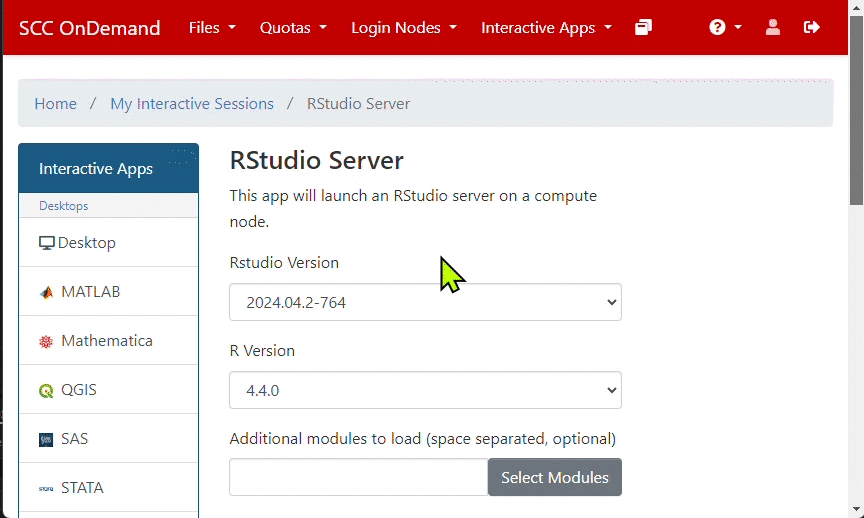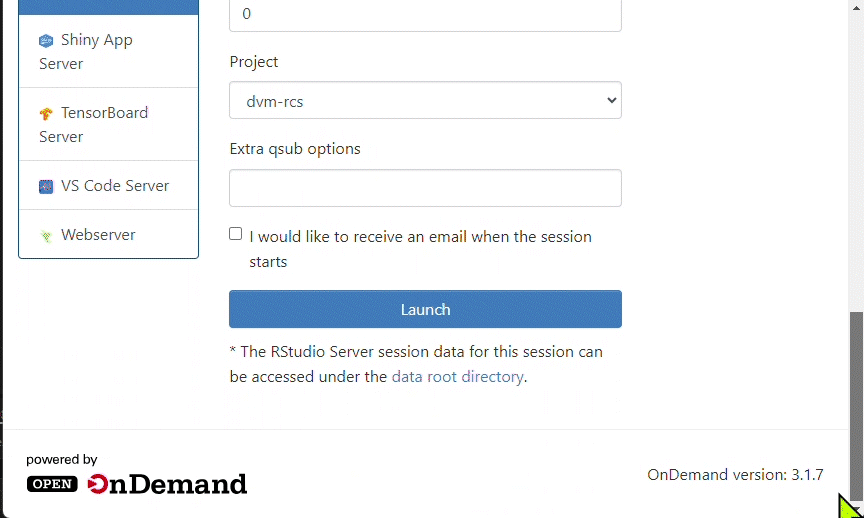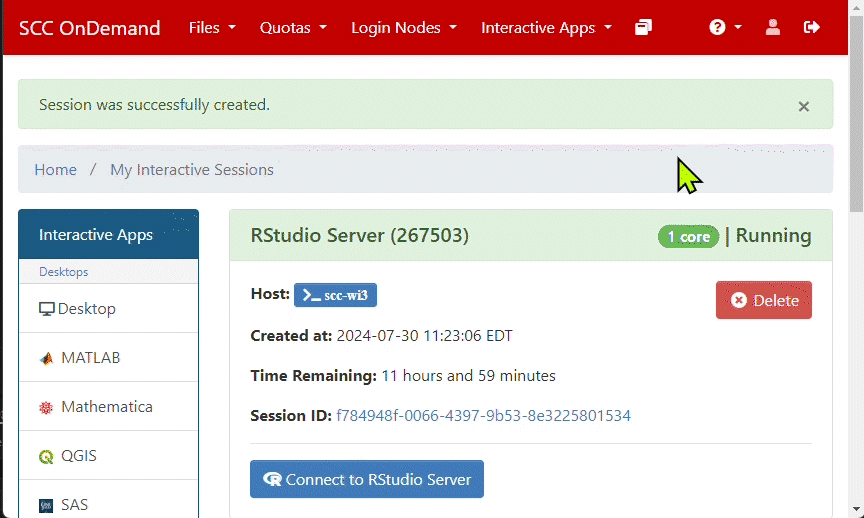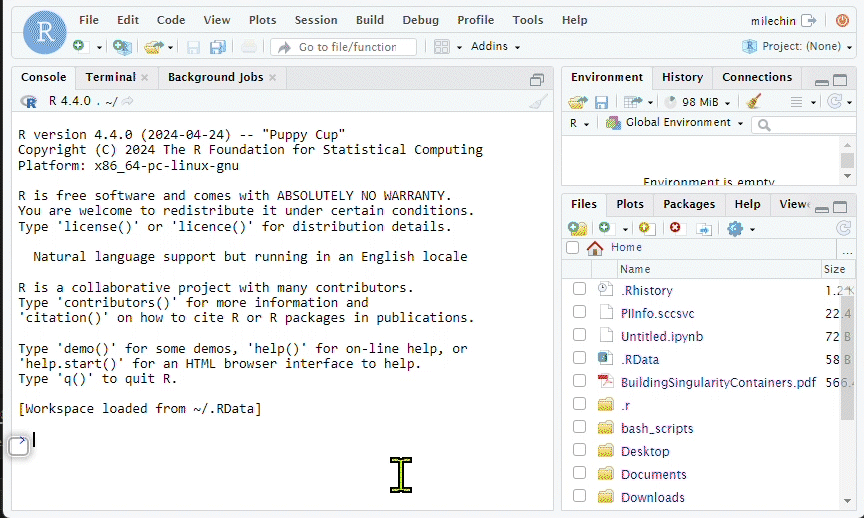
- Click on Interactive Apps and then on RStudio Server.
- In the drop down menus select the latest version of RStudio and a version of R you wish to load. Additionally, specify number of hours and cores for the job.
NOTE: If you belong to more than one SCC project, select the appropriate project in the “Project” drop down menu at the bottom of the form.
- Click Launch to submit the job request. Once the job status changes from Queued to Running, click Connect to RStudio Server button to connect to the RStudio session.
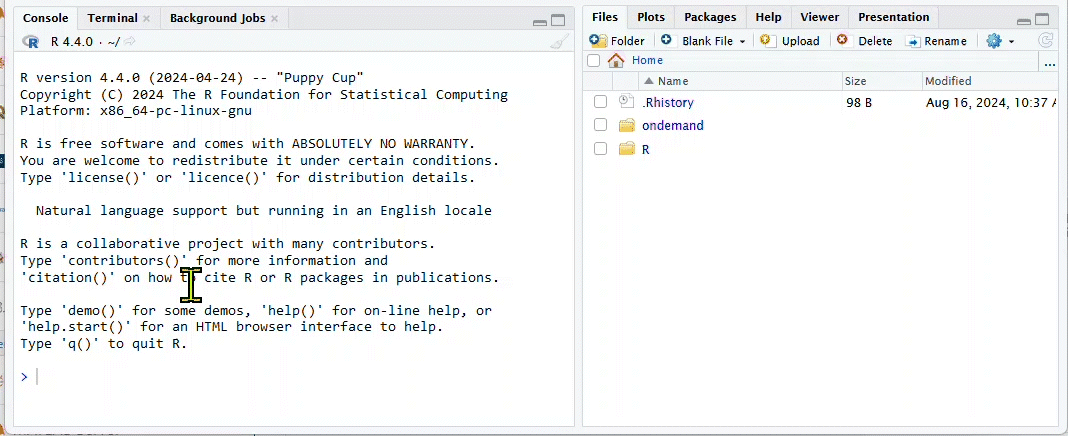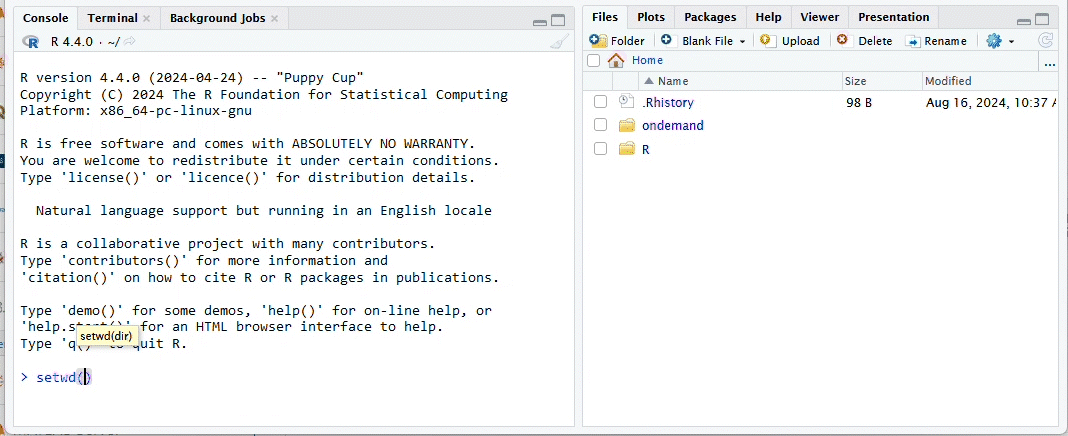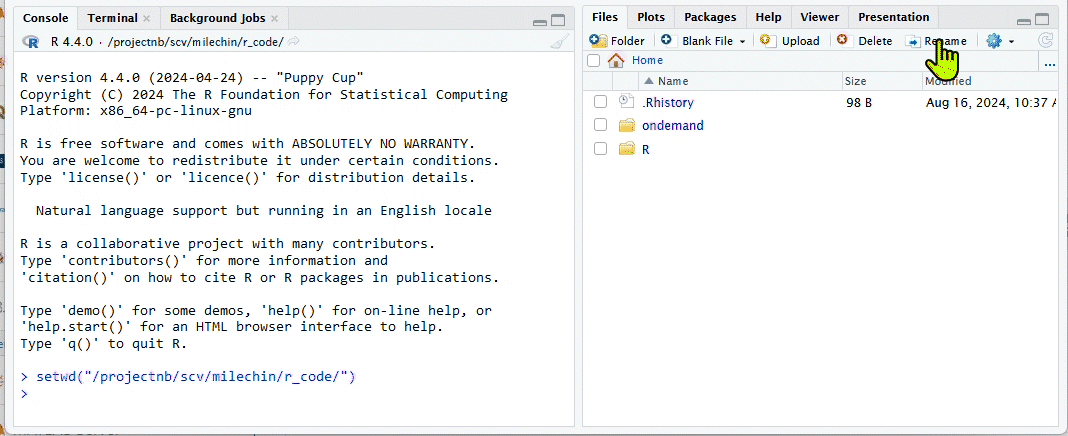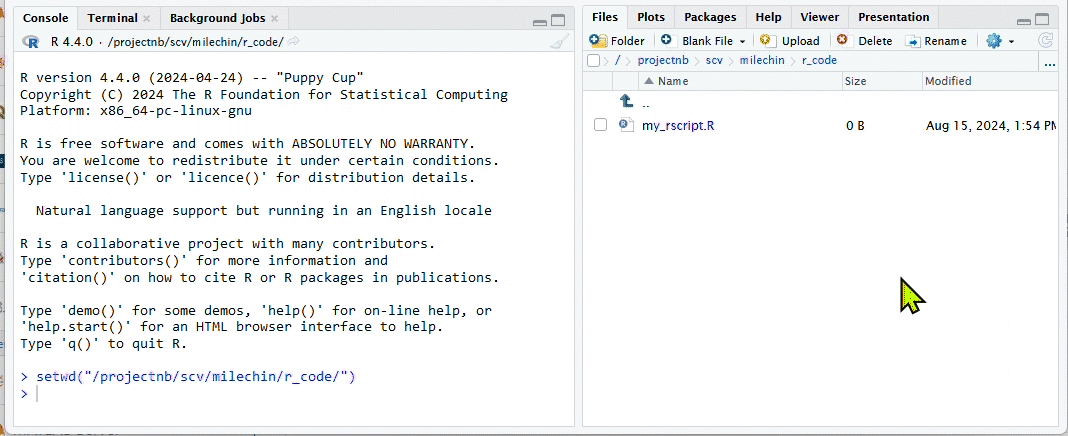
- After connecting to the RStudio session, set your working directory to the appropriate SCC project directory using setwd() function. Then set the “File” pane to the working directory by clicking the blue gear icon and click “Go to working directory”.
- Click on the “Packages” tab to see a list of R packages already installed and ready for your use. You can install your own R Packages if you need one that is not listed in the “Packages” tab.
Starting R Console within a Terminal
- Open a terminal connected to the SCC.
- Print the available versions of R by executing the following command:
scc1$ module spider R - Use the module load command to load the version of R desired and then run the R executable to start the R console within the terminal.
scc1$ module load R/4.4.0 scc1$ R - To list all the R Packages already installed, run the following installed.packages() command:
> installed.packages()[,c("Package", "Version")] - To exit the R console, execute the quit function:
> q()
Installing R Packages
Researchers are able to install their own R packages on the SCC. By default, these packages will be installed in the Home directory (~/R/x86_64-pc-linux-gnu-library/4.X). When installing a package for the first time, you maybe prompted with questions about creating this directory in your Home directory. The first question will ask if you want to use a “personal library”, as an example shows below.
> install.packages("tidycensus")
Installing package into ‘/usr1/project/username/R/x86_64-pc-linux-gnu-library/4.4’ (as ‘lib’ is unspecified)
Warning in install.packages : 'lib = "/usr1/project/username/R/x86_64-pc-linux-gnu-library/4.4"' is not writable
Would you like to use a personal library instead? (yes/No/cancel)Type in yes and hit Enter key.
The second question will ask you to confirm the location of the personal library and propose a default location in your home directory:
Would you like to create a personal library
‘/usr1/scv/milechin/R/x86_64-pc-linux-gnu-library/4.4’
to install packages into? (yes/No/cancel) Type in yes and hit Enter key to accept the default location.
After the directory is created, the installation should proceed as normal. If you have an issue installing an R package, please fill out the Software Request Form to get assistance from our team.
Additional Help/Documentation
Internal Resources
- Introduction to Using R and RStudio on the SCC– a 20 minute introduction video
- Recorded Tutorials – See “Data Analysis Tutorial” section.
- R Frequently Asked Questions
- R example scripts
- Parallelization and optimization techniques and tutorial scripts
- Upcoming Workshops – see “Data Analysis Tutorials” section.