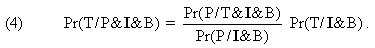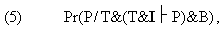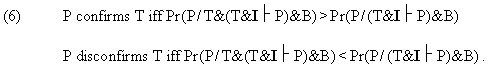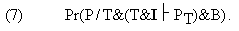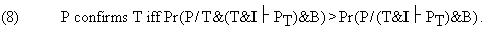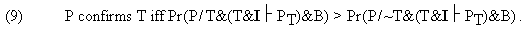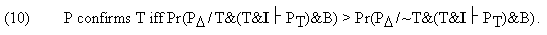|
The Bayesian Theory of Confirmation, Idealizations and Approximations in Science Erdinç Sayan
|
|
The Bayesian Theory of Confirmation, Idealizations and Approximations in Science Erdinç Sayan
|
Idealizations and approximations like
point-masses, perfectly elastic springs, parallel conductors crossing at
infinity, assumptions of linearity, of "negligible" masses, of perfectly
spherical shapes, are commonplace in science. Use of such simplifying
assumptions as catalysts in the process of deriving testable predictions
from theories complicates our picture of confirmation and
disconfirmation. Underlying the difficulties is the fact that idealizing
and approximating assumptions are already known to be
false statements, and yet they are often indispensable when testing
theories for truth. This aspect of theory testing has been long
neglected or misunderstood by philosophers. In standard
hypothetico-deductive, bootstrapping and Bayesian accounts of
confirmation, idealizations and approximations are simply ignored. My
focus in this paper is on how the basic Bayesian model can be amended to
reflect the role of idealizations and approximations in the confirmation
or disconfirmation of an hypothesis. I suggest the following as a
plausible way of incorporating idealizations and approximations into the
Bayesian condition for incremental confirmation: Theory T is confirmed
by observation P relative to background knowledge Idealizations enter into scientific analysis or explanation in a couple of ways. An idealization may be contained within the law or theory itself. For example, insofar as Newton's second law is conceived as applying only to point-masses, that law contains an idealization as part of its content. Sometimes idealizations take the form of assumptions conjoined to a theory from outside. For instance, assuming that the universe contains only two bodies is an idealization that may be employed in some contexts as input to Newton's law of gravitation and second law of motion. Scientists must resort to idealizations and approximations for several reasons. There may be the lack of, (i) necessary data to required accuracy, (ii) mathematical-analytical or computational power, (iii) necessary auxiliary theories. Without idealizing and simplifying assumptions such as frictionless planes, weightless strings, isolated thermodynamic systems, perfectly elastic bodies, perfectly uniform electric fields, and the like, working out the implications of theories is often impracticable. Computational facilitation afforded by idealizations and simplifications make them vital elements of scientific activity. Despite the pervasive use of idealizations and approximations in science, their role has been ignored or misunderstood by philosophers. Idealizing and simplifying assumptions are strictly speaking false statements, hence they amount to distortions of reality. Still, interestingly, they are routinely employed in explanations of phenomena or when testing a scientific theory for truth. The role of idealizing and simplifying assumptions is especially important for theories of confirmation to account for. Yet, well-known theories of confirmation, such as the hypothetico-deductive, bootstrapping and Bayesian approaches, appear largely oblivious to the relevance of idealizations and approximations to confirmation. In testing contexts, the interaction between a theory and the idealizations under which it operates is an interaction of (putative) truth (of the theory) with falsehood (of the idealizations and approximations). This facet of theory testing deserves more attention than it has received from philosophers of science. In this paper I shall look at how the Bayesian account of confirmation can square with idealizations and approximations. (1) According to the standard Bayesian conception of testing, the incremental confirmation or disconfirmation of an hypothesis by a given piece of evidence requires comparison of the prior probability of the hypothesis with the posterior probability of that hypothesis on that evidence (where those probabilities are understood as subjective probabilities, or degrees of belief, conforming to the probability axioms). Let the hypothesis be theory T, the evidence be the prediction P of the theory, and let 'B' denote the background knowledge relative to which the theory is being tested. The Bayesian criteria for confirmation and disconfirmation are given as: (1) P confirms T iff Pr(P/T&B)>Pr(P/B) P disconfirms T iff Pr(P/T&B)<Pr(P/B). The posterior probability Pr(T/P&B) of the theory is related to its prior probability Pr(T/B) by Bayes's theorem as follows:
From (1) and (2) another set of necessary and sufficient conditions are obtained for incremental confirmation and disconfirmation of T by P relative to B: (3) P confirms T iff Pr(P/T&B)>Pr(P/B) P disconfirms T iff Pr(P/T&B)<Pr(P/B). How does the Bayesian model sketched above accommodate the role of idealizations and approximations in the confirmation and disconfirmation of T? In other words, where do the idealizing assumptions and approximations figure in the Bayesian framework? In standard Bayesian treatments of scientific reasoning, they simply don't; they are entirely left out of the picture. But, as we shall see, idealizations and approximations pose challenges that the Bayesian model of confirmation. indeed any theory of confirmation. must cope with. To see the problems involved, let us focus on the expression Pr(P/T&B), called "the likelihood of P." Pr(P/T&B) stands for the probability that we assign to observation P on the basis of theory T plus our background knowledge and beliefs B. Now, as we have said, in most testing situations if we didn't employ any idealizations and approximations, analytic and computational hardships would make it impossible for us to derive P as a prediction from T. And without the ability to derive P from T, we might fail to assign to Pr(P/T&B) the value it deserves. For when we are unable to see that P is deducible from T, even though the deduction requires mediation of some idealizations and approximations, our estimate of the value of Pr(P/T&B) couldn't be much different from that of Pr(P/B). In that case, it follows by (3) that no incremental confirmation or disconfirmation of T by P would be gained. To illustrate this point, suppose that we are wondering if P, the observed period of a certain pendulum, provides any incremental confirmation for T, the Newtonian laws of motion. Also suppose, for the sake of the example, that the Newtonian laws have been newly conceived and that they have not been tested by a lot of observations yet. Without the ability to derive the period of the pendulum from the Newtonian laws, albeit by employing some idealizations and simplifications, (2) we wouldn't have any antecedent idea what the period might be, given Newtonian laws, other than what our general background knowledge or experience about the world would lead us to expect about the value of the period. That is to say, without such ability, we couldn't but assign to the likelihood Pr(P/T&B) of the period a value which is (almost) the same as the value we assign to its prior likelihood Pr(P/B). Consequently, the period of the pendulum could not serve as evidence for the Newtonian laws as it should. Therefore when P, such as the period of a pendulum, has been derived from T, such as the Newtonian theory, with the help of some idealizations and approximations (the conjunction of which we shall hereafter denote by 'I'), this fact needs to be duly represented in the Bayesian scheme. For I is clearly an important part of the confirmation or disconfirmation of T by P. The question is, How? Let us start with the suggestion that I should appear as a conjunct in the condition clause (i.e. the right-hand side of the slash ('/')) of the likelihood of P. This suggestion might be an attempt to reflect the fact that prediction P was derived not from T alone but from T in conjunction with I. Thus let us have Pr(P/T&I&B) for the likelihood of P instead of Pr(P/T&B). This amounts to making I part of the background knowledge, i.e. expanding the background knowledge into I&B. With this new background knowledge, (2) becomes:
But this suggestion wouldn't do. As we have said, idealizations are false statements given what we know about the world, which is to say that I is inconsistent with B. Therefore I&B leads to contradiction. It follows from probability theory then that every probability expression in (4) takes on the value 1. This of course is not a pleasant result. Another suggestion might be to incorporate the information that P was
derived from T in conjunction with I, into the background
knowledge. That is, to make T&I
and the criteria in (3) now need to be rewritten as:
Now, what value can we assign to the probability expression (5)? The condition clause of (5) demands that we assume that T is true and that T together with I entails P. On the other hand, we know from B that I is false. So the probability we are considering in (5) is the probability of a true P (since P is an observation actually made) following deductively from an assumedly true T conjoined with a false I. A little reflection shows that this can happen only if the errors or falsehoods due to I cancel out during the computational derivation of P from T&I. For, if the errors introduced by I do not cancel out one another, we can't obtain a true prediction from a true T conjoined to I, since those errors should cause distortion (from truth) on our prediction. (3) Hence the likelihood of P expressed in (5) is nothing but the probability that the errors caused by I would completely nullify one another during the process of derivation of P from T&I, given all that we know (viz. B) and under the assumption that T is true. There are a couple of problems with (5). First, can we really assign any probability value to occurrence of a complete cancellation of errors during the derivation of P? Remember that the reason we resort to idealizations in the first place is that we lack the ability to quantitatively handle all the variables involved in the case. When idealizing assumptions are imperative computationally, it usually happens that a quantitative grasp of the interaction of errors they create is beyond our reach. More often than not, the best we have got are hunches to the effect that the distortion brought by our idealizations and approximations on our prediction must be "insignificant" or "negligible," but we are far from being able to turn such hunches into probability distributions for the range of errors. In response, at least some Bayesians might argue that even though it may be infeasible for real people to come up with the requisite probability assignments, e.g. to total error cancellation, those values nevertheless exist, perhaps for an agent "perfectly rational and competent in error-probability computation," and the Bayesian criteria of confirmation and disconfirmation are intended for some such idealized agent. Leaving aside for the time being the issue of the adequacy of this response to the question, a decisive objection to (5), and hence to (6), would be the following. In (5) and (6) the actual observation (represented by 'P' on the left-hand side of the slash in the probability expressions in (5) and (6)) is exactly what is predicted (represented by the 'P' that occurs on the right-hand side of the slash in those expressions). Therefore (6) restricts the cases of theory testing to those where the prediction from the theory exactly (or almost exactly) matches reality. But such cases are rare, because, as we have said, a complete cancellation of errors, which must take place if the prediction is to closely match reality, is a rare occurrence. What usually happens in actual testing situations is that the theory in conjunction with I entails PT, which differs more or less from the actual observation P. The confirmation/disconfirmation decision is then made on the basis of the size of the discrepancy between the observation P and the prediction PT: if the discrepancy is regarded as "sufficiently small," the theory may be judged by the scientist to be confirmed; if the discrepancy seems "too large," the theory may be taken to be disconfirmed. So the following version of the likelihood of P purports to be better reflective of what predominantly happens in actual practice:
Accordingly, the Bayesian condition for confirmation can be written as:
Similarly for the disconfirmation condition. Does (8) finally capture in a Bayesian format the role of idealizations and approximations in testing of theories? I think there is reason for optimism. Let us first point out that we can give an alternative formulation to the Bayesian condition for confirmation which is equivalent to that in (8) and is perhaps intuitively more accessible:
In (9), '~T' stands for the negation of the theory. (4) Thus in accordance with (9), P confirms T just in case the fact that T&I entails PT renders P more probable on the supposition that T is true than on the supposition that T is false. An alternative to treating P as the evidence is to take PD to be the evidence, where 'PD' expresses the magnitude of the discrepancy between P and PT; that is, PD states how far off the mark PT is. The condition then takes the form:
Put in words: T is confirmed by an observation just in case the truth of T makes the discrepancy between the prediction and the observation more probable than does the falsehood of T, given all that we know. Thus in (9) and (10) we are to compare two probabilities, one associated with the assumption that our theory is true, the other associated with the assumption that it is false. How feasible are those probability comparisons to actually make? The question is pertinent in the face of the fact, which we have pointed out earlier, that oftentimes we cannot quantitatively monitor the behavior of errors in I. (5) I think we are not without a heuristic aid in performing those
comparisons in many cases. My intuition is that the notion of explanatory
strength or explanatory credibility is intimately related to the notion of
probability. In many circumstances we find the explanation of a phenomenon
on the basis of the truth of an hypothesis more credible than on the basis
of its falsehood. In those cases we think the phenomenon would have a
higher probability to occur on the assumption of the truth of the theory
than on the assumption of its falsehood. Suppose I am shooting at a target
in a shooting-gallery with my new gun. The distribution of the bullet
holes on the target board suggests to me the hypothesis that there is
something wrong with the aiming mechanism of my gun. What leads me to
think so is the consideration that the average distance of the bullet
holes from the bull's-eye is larger than it would have been if my gun was
not defective. (Here, the non-defective-gun hypothesis is T, the
defective-gun hypothesis is ~T, the bull's-eye is the predicted location
of my hits, PT, and the observed average deviation of the bullet holes
from the bull's-eye is P.) In other words, taking into consideration all
the factors which I believe to be normally responsible for my small
deviations from the bull's-eye (my neglecting of some of these factors and
treating them as "idealizations and approximations" enable me to derive PT
from T), the discrepancy between my prediction and my observation cannot
be convincingly explained except by a manufacturing defect in the gun.
Hence the truth of my defective-gun hypothesis explains or accounts for
the data better for me than does the truth of the non-defective-gun
hypothesis. This fact is also what makes me think that the data
confirms the defective-gun hypothesis. These judgments would seem
to have a translation in the language of subjective probability: The truth
of my defective-gun hypothesis would make my antecedent degree of belief
in (or expectation of) the data stronger, under the circumstances, than
would the truth of the non-defective-gun hypothesis. In probabilistic
terms, Pr(P/T&(T&I The above reasoning linking the notions of explanatory strength and subjective probability suggests the following non-probabilistic parallel of the confirmation conditions (9) and (10): (11) P (alternatively, PD) confirms T iff, given that T&I entails PT, truth of T better explains, for all we know, the observation P (PD) than does the falsehood of T. To the extent that better explainability is a sufficient condition for higher probability, the confirmation condition (11) could replace (9) and (10). However, I am not prepared to offer an explication of the notion of an explanation in terms of the truth of an hypothesis being better or worse than an alternative explanation in terms of the falsehood of that hypothesis. I want here only to point to the idea as a possibility. (6) The idea may be worth pursuing for the following reason. Whereas (9) and (10) are vulnerable to the notorious "problem of old evidence," which still awaits a generally accepted solution, (7) (11) isn't. Thus (11) would seem to have an edge on its Bayesian analogues (9) and (10). On the down side, dispensing with (9) and (10) in favor of (11) means adopting a qualitative concept of confirmation (unless the notion of explanatory strength can be quantified) and hence losing what is valued by Bayesians as a clear advantage of their approach over its competitors. a quantitative concept of confirmation built on the notion of probability.
|
Bibliography Achinstein, Peter, ed. 1983. The Concept of Evidence. New York: Oxford University Press. ________. 1993. "Explanation and 'Old Evidence'," Philosophica, 51, pp.125-137. Chihara, Charles S. 1987. "Some Problems for Bayesian Confirmation Theory," British Journal for the Philosophy of Science, 38, pp.551-560. Earman, John. 1992. Bayes or Bust? Cambridge and London: The MIT Press. Eells, Ellery. 1985. "Problems of Old Evidence," Pacific Philosophical Quarterly, 66, pp.283-302. Garber, Daniel. 1983. "Old Evidence and Logical Omniscience in Bayesian Confirmation Theory," in John Earman (ed.), Testing Scientific Theories. Minneapolis: University of Minnesota Press, pp.99-131. Glymour, Clark. 1980. Theory and Evidence. Princeton: Princeton University Press. Horwich, Paul. 1982. Probability and Evidence. Cambridge and London: Cambridge University Press. Howson, Colin. 1985. "Some Recent Objections to the Bayesian Theory of Support," British Journal for the Philosophy of Science, 36, pp.305-309. ________. 1991. "The 'Old Evidence' Problem," British Journal for the Philosophy of Science, 42, pp.547-555. Jeffrey, Richard. 1983. "Bayesianism with a Human Face," in John Earman (ed.), Testing Scientific Theories. Minneapolis: University of Minnesota Press, pp.133-156. Laymon, Ronald. 1985. "Idealizations and the Testing of Theories by Experimentation," in Peter Achinstein and Owen Hannaway (eds.), Observation, Experiment, and Hypothesis in Modern Physical Science. Cambridge: The MIT Press, pp.147-173. Niiniluoto, Ilkka. 1983. "Novel Facts and Bayesianism," British Journal for the Philosophy of Science, 34, pp.375-379. Notes (1) For an illuminating discussion of the serious problems that the use of idealizations present for the hypothetico-deductive theory of confirmation, see Laymon 1985, pp.147-155. I believe the kind of problems Laymon displays for the hypothetico-deductive model also haunt Glymour's bootstrapping account of confirmation found in Glymour 1980, Ch.5. (2) Such as the assumptions that the bob of the pendulum is a point-mass, that its string is weightless, that the angle of swing is small, etc., which are resorted to in introductory physics textbooks to facilitate the otherwise difficult derivation of the period of the pendulum from Newton's laws. (3) This point is nicely illustrated in Laymon 1985, pp.148-154. For an atrociously simplified example in which the errors propagated by I cancel out to yield a true prediction from a true theory, consider: T: All ravens are birds, I: All birds are red&All red things are black, P: The next raven to be observed is black. (4) We can show that the confirmation
condition in (3), viz. Pr(P/T&B) > Pr(P/B), holds if and only if
Pr(P/T&B) > Pr(P/~T&B) holds (provided Pr(T/B) ¹1). First, let us note that Pr(P/B) =
[Pr(P/T&B)Pr(T/B)] (5)As Laymon points out, sometimes we are able to work out a quantitative error analysis to find out what amount of error in input variables results in what amount of error in the output PT. In such cases, (7) takes on either the value 1 or 0, depending on whether or not the discrepancy between P and PT is what is calculated by the error analysis. But when the computations needed to extract a prediction from the theory are complex, as happens frequently, we are forbidden from an error analysis (Laymon 1985, pp.150-154). In those cases, we can at best "guesstimate" what the amount of error in our prediction may have been, and correspondingly, we can only guesstimate the probability distribution of the discrepancies in question. Thus, more often than not, our assignment of a value to (7) has to be based on hunches and intuitive judgments. But using guesstimates and intuitive determinations is an essential part of the Bayesian methodology, e.g. when determining the prior probability of the hypothesis or the prior likelihood of the prediction. (6) Achinstein has offered an account of confirmation that utilizes the notion of explanatory connection between the theory and its putative evidence, in addition to employing the notion of probability. See Achinstein 1983, Ch.8, and Achinstein 1993. (7) This problem with the Bayesian notion of incremental confirmation was discovered by Glymour (see Glymour 1980, pp.85-93). One type of strategy for solution is followed in Horwich 1982 (pp.52-53) and Howson 1985 and 1991, another is worked out in Garber 1983, Jeffrey 1983 and Niiniluoto 1983. For a criticism of the first kind of strategy, see Chihara 1987 and Eells 1985; for a criticism of the second, see Earman 1992, Ch.5.
|
|
Paideia logo design by Janet L. Olson. |
|

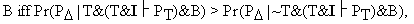
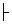 stands for logical entailment. This
formulation has the virtue of explicitly taking into account the
essential use made of idealizations and approximations as well as the
fact that theoretically based predictions that utilize such assumptions
will not, in general, exactly fit the data. A non-probabilistic analogue
of the confirmation condition above that I offer avoids the 'old
evidence problem,' which has been a headache for classical
Bayesianism.
stands for logical entailment. This
formulation has the virtue of explicitly taking into account the
essential use made of idealizations and approximations as well as the
fact that theoretically based predictions that utilize such assumptions
will not, in general, exactly fit the data. A non-probabilistic analogue
of the confirmation condition above that I offer avoids the 'old
evidence problem,' which has been a headache for classical
Bayesianism.