.
Sen Fang, Chunyu Sui, Honwei Yi, Carol Neidle, and Dimitris Metaxas (2025) SignX: The Foundation Model for Sign Recognition. arXiv:2504.16315 [cs.CV] pp. 1-12 .
https://doi.org/10.48550/arXiv.2504.16315. https://arxiv.org/abs/2504.16315Abstract. The complexity of sign language data processing brings many challenges. The current approach to recognition of ASL signs aims to translate RGB sign language videos through pose information into English-based ID glosses, which serve to uniquely identify ASL signs. Note that there is no shared convention for assigning such glosses to ASL signs, so it is essential that the same glossing conventions are used for all of the data in the datasets that are employed. This paper proposes SignX, a foundation model framework for sign recognition. It is a concise yet powerful framework applicable to multiple human activity recognition scenarios. First, we developed a Pose2Gloss component based on an inverse diffusion model, which contains a multi-track pose fusion layer that unifies five of the most powerful pose information sources--SMPLer-X, DWPose, Mediapipe, PrimeDepth, and Sapiens Segmentation--into a single latent pose representation. Second, we trained a Video2Pose module based on ViT that can directly convert raw video into signer pose representation. Through this 2-stage training framework, we enable sign language recognition models to be compatible with existing pose formats, laying the foundation for the common pose estimation necessary for sign recognition. Experimental results show that SignX can recognize signs from sign language video, producing predicted gloss representations with greater accuracy than has been reported in prior work.
Carol Neidle, Augustine Opoku, Carey Ballard, Yang Zhou, Xiaoxiao He, and Dimitris Metaxas (2024) New Capability to Look Up an ASL Sign from a Video Example.
https://arxiv.org/abs/2407.13571
arXiv:2407.13571 [cs.CV] pp. 1-11 https://doi.org/10.48550/arXiv.2407.13571BU Open Access: https://open.bu.edu/handle/2144/49141
Abstract. Looking up an unknown sign in an ASL dictionary can be difficult. Most ASL dictionaries are organized based on English glosses, despite the fact that (1) there is no convention for assigning English-based glosses to ASL signs; and (2) there is no 1-1 correspondence between ASL signs and English words. Furthermore, what if the user does not know either the meaning of the target sign or its possible English translation(s)? Some ASL dictionaries enable searching through specification of articulatory properties, such as handshapes, locations, movement properties, etc.. However, this is a cumbersome process and does not always result in successful lookup. Here we describe a new system, publicly shared on the Web, to enable lookup of a video of an ASL sign (e.g., a webcam recording or a clip from a continuous signing video). The user submits a video for analysis and is presented with the five most likely sign matches, in decreasing order of likelihood, so that the user can confirm the selection before being taken to our ASLLRP Sign Bank entry for that sign. Furthermore, this video lookup is also integrated into our newest version of SignStream® software to facilitate linguistic annotation of ASL video data, enabling the user to directly look up a sign in the video being annotated, and, upon confirmation of the match, to directly enter into the annotation the gloss and features of that sign, greatly increasing the efficiency and consistency of linguistic annotations of ASL video data.
Zhaoyang Xia, Yang Zhou, Ligong Han, Carol Neidle, and Dimitris Metaxas (2024) Diffusion Models for Sign Language Video Anonymization. Proceedings of the LREC-COLING 2024 11th Workshop on the Representation and Processing of Sign Languages: Evaluation of Sign Language Resources (Torino, Italy, May 25, 2024). ELRA Language Resources Association (ELRA) and the International Committee on Computational Linguistics (ICCL).
https://www.sign-lang.uni-hamburg.de/lrec/pub/24014.pdf
BU Open Access: https://hdl.handle.net/2144/48967
Abstract. Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, this does not preserve privacy. Since critical linguistic information is transmitted through facial expressions, the face cannot be obscured. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success and generally require pose estimation that cannot be readily carried out in the wild. To address current limitations, our research introduces DiffSLVA, a novel methodology that uses pre-trained large-scale diffusion models for text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module to capture linguistically essential facial expressions. We then combine the above methods to achieve anonymization that preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities.
https://www.sign-lang.uni-hamburg.de/lrec2024/programme.html
Yang Zhou, Zhaoyang Xia, Yuxiao Chen, Carol Neidle, and Dimitris N. Metaxas (2024) A Multimodal Spatio-Temporal GCN Model with Enhancements for Isolated Sign Recognition. Proceedings of the LREC-COLING 2024 11th Workshop on the Representation and Processing of Sign Languages: Evaluation of Sign Language Resources (Torino, Italy, May 25, 2024). ELRA Language Resources Association (ELRA) and the International Committee on Computational Linguistics (ICCL).
https://www.sign-lang.uni-hamburg.de/lrec/pub/24015.pdf
BU Open Access: https://hdl.handle.net/2144/48968
Abstract. We propose a multimodal network using skeletons and handshapes as input to recognize individual signs and detect their boundaries in American Sign Language (ASL) videos. Our method integrates a spatio-temporal Graph Convolutional Network (GCN) architecture to estimate human skeleton keypoints; it uses a late-fusion approach for both forward and backward processing of video streams. Our (core) method is designed for the extraction— and analysis of features from—ASL videos, to enhance accuracy and efficiency of recognition of individual signs. A Gating module based on per-channel multi-layer convolutions is employed to evaluate significant frames for recognition of isolated signs. Additionally, an auxiliary multimodal branch network, integrated with a transformer, is designed to estimate the linguistic start and end frames of an isolated sign within a video clip. We evaluated performance of our approach on multiple datasets that include isolated, citation-form signs and signs presegmented from continuous signing based on linguistic annotations of start and end points of signs within sentences. We have achieved very promising results when using both types of sign videos combined for training, with overall sign recognition accuracy of 80.8% Top-1 and 95.2% Top-5 for citation-form signs, and 80.4% Top-1 and 93.0% Top-5 for signs pre-segmented from continuous signing.
https://www.sign-lang.uni-hamburg.de/lrec2024/programme.html
Zhaoyang Xia, Carol Neidle, and Dimitris Metaxas (2023) DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization. November 2023.
arXiv:2311.16060 [cs.CV] pp. 1-11
https://doi.org/10.48550/arXiv.2311.16060
BU Open Access: https://hdl.handle.net/2144/48000
Abstract. Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos ’in the wild,’ in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.
Carol Neidle (2023) Challenges for Linguistically-Driven Computer-Based Sign Recognition from Continuous Signing for American Sign Language. November 2023.
arXiv:2311.00762 [cs.CV] pp. 1-32
https://doi.org/10.48550/arXiv.2311.00762BU Open Access: https://hdl.handle.net/2144/48002
Abstract. There have been recent advances in computer-based recognition of isolated, citation-form signs from video. There are many challenges for such a task, not least the naturally occurring inter- and intra- signer synchronic variation in sign production, including sociolinguistic variation in the realization of certain signs. However, there are several significant factors that make recognition of signs from continuous signing an even more difficult problem. This article presents an overview of such challenges, based in part on findings from a large corpus of linguistically annotated video data for American Sign Language (ASL). Some linguistic regularities in the structure of signs that can boost handshape and sign recognition are also discussed.
Saad Hassan, Sooyeon Lee, Dimitris Metaxas, Carol Neidle, and Matt Huenerfauth (2022) Understanding ASL Learners’ Preferences for a Sign Language Recording and Automatic Feedback System to Support Self-Study. ASSETS 2022.
https://dl.acm.org/doi/abs/10.1145/3517428.3550367
BU Open Access: https://hdl.handle.net/2144/45440
Abstract. Advancements in AI will soon enable tools for providing automatic feedback to American Sign Language (ASL) learners on some aspects of their signing, but there is a need to understand their preferences for submitting videos and receiving feedback. Ten participants in our study were asked to record a few sentences in ASL using software we designed, and we provided manually curated feedback on one sentence in a manner that simulates the output of a future automatic feedback system. Participants responded to interview questions and a questionnaire eliciting their impressions of the prototype. Our initial findings provide guidance to future designers of automatic feedback systems for ASL learners.
Carol Neidle, Augustine Opoku, Carey Ballard, Konstantinos M. Dafnis, Evgenia Chroni, and Dimitris Metaxas (2022). Resources for Computer-Based Sign Recognition from Video, and the Criticality of Consistency of Gloss Labeling across Multiple Large ASL Video Corpora. 10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources. LREC, Marseille, France, June 2022.
Proceedings of the LREC2022 10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources, Marseille, France, 25 June 2022. pp. 165-172.
BU Open Access: https://hdl.handle.net/2144/45152
Abstract. The WLASL purports to be “the largest video dataset for Word-Level American Sign Language (ASL) recognition.” It brings together various publicly shared video collections that could be quite valuable for sign recognition research, and it has been used extensively for such research. However, a critical problem with the accompanying annotations has heretofore not been recognized by the authors, nor by those who have exploited these data: There is no 1-1 correspondence between sign productions and gloss labels. Here we describe a large (and recently expanded and enhanced), linguistically annotated, downloadable, video corpus of citation-form ASL signs shared by the American Sign Language Linguistic Research Project (ASLLRP)—with 23,452 sign tokens and an online Sign Bank—in which such correspondences are enforced. We furthermore provide annotations for 19,672 of the WLASL video examples consistent with ASLLRP glossing conventions. For those wishing to use WLASL videos, this provides a set of annotations that makes it possible: (1) to use those data reliably for computational research; and/or (2) to combine the WLASL and ASLLRP datasets, creating a combined resource that is larger and richer than either of those datasets individually, with consistent gloss labeling for all signs. We also offer a summary of our own sign recognition research to date that exploits these data resources.
Zhaoyang Xia, Yuxiao Chen, Qilong Zhangli, Matt Huenerfauth, Carol Neidle, and Dimitris Metaxas, D. (2022). Sign Language Video Anonymization.10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources. LREC, Marseille, France, June 2022.
Proceedings of the LREC2022 10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources, Marseille, France, 25 June 2022. pp. 202-211.
BU Open Access: https://hdl.handle.net/2144/45151
Abstract. Deaf signers who wish to communicate in their native language frequently share videos on the Web. However, videos cannot preserve privacy---as is often desirable for discussion of sensitive topics---since both hands and face convey critical linguistic information and therefore cannot be obscured without degrading communication. Deaf signers have expressed interest in video anonymization that would preserve linguistic content. However, attempts to develop such technology have thus far shown limited success. We are developing a new method for such anonymization, with input from ASL signers. We modify a motion-based image animation model to generate high-resolution videos with the signer identity changed, but with the preservation of linguistically significant motions and facial expressions.
An asymmetric encoder-decoder structured image generator is used to generate the high-resolution target frame from the low-resolution source frame based on the optical flow and confidence map. We explicitly guide the model to attain a clear generation of hands and faces by using bounding boxes to improve the loss computation. FID and KID scores are used for the evaluation of the realism of the generated frames. This technology shows great potential for practical applications to benefit deaf signers.Konstantinos M. Dafnis, Evgenia Chroni, Carol Neidle, and Dimitris Metaxas (2022). Isolated Sign Recognition using ASL Datasets with Consistent Text-based Gloss Labeling and Curriculum Learning. Seventh International Workshop on Sign Language Translation and Avatar Technology: The Junction of the Visual and the Textual (SLTAT 2022). LREC, Marseille, France, June 2022.
Proceedings of the LREC2022 Seventh International Workshop on Sign Language Translation and Avatar Technology: The Junction of the Visual and the Textual (SLTAT 2022), Marseille, France, 24 June 2022. pp. 13-20.
BU Open Access:https://hdl.handle.net/2144/45153
Abstract. We present a new approach for isolated sign recognition, which combines a spatial-temporal Graph Convolution Network (GCN) architecture for modeling human skeleton keypoints with late fusion of both the forward and backward video streams, and we explore the use of curriculum learning. We employ a type of curriculum learning that dynamically estimates, during training, the order of difficulty of each input video for sign recognition; this involves learning a new family of data parameters that are dynamically updated during training. The research makes use of a large combined video dataset for American Sign Language (ASL), including data from both the American Sign Language Lexicon Video Dataset (ASLLVD) and the Word-Level American Sign Language (WLASL) dataset, with modified gloss labeling of the latter—to ensure 1-1 correspondence between gloss labels and distinct sign productions, as well as consistency in gloss labeling across the two datasets. This is the first time that these two datasets have been used in combination for isolated sign recognition research. We also compare the sign recognition performance on several different subsets of the combined dataset, varying in, e.g., the minimum number of samples per sign (and therefore also in the total number of sign classes and video examples).
Konstantinos M. Dafnis, Evgenia Chroni, Carol Neidle, and Dimitris Metaxas (2022). Bidirectional Skeleton-Based Isolated Sign Recognition using Graph Convolution Networks. LREC 2022, https://lrec2022.lrec-conf.org/en/, June 20-25, 2022.
Proceedings of the 13th Conference on Language Resources and Evaluation (LREC 2022), Marseille, 20-25 June 2022. pp. 7328–7338.
BU Open Access: https://hdl.handle.net/2144/45154
Abstract. To improve computer-based recognition from video of isolated signs from American Sign Language (ASL), we propose a new skeleton-based method that involves explicit detection of the start and end frames of signs, trained on the ASLLVD dataset; it uses linguistically relevant parameters based on the skeleton input. Our method employs a bidirectional learning approach within a Graph Convolutional Network (GCN) framework. We apply this method to the WLASL dataset, but with corrections to the gloss labeling to ensure consistency in the labels assigned to different signs; it is important to have a 1-1 correspondence between signs and text-based gloss labels. We achieve a success rate of 77.43% for top-1 and 94.54% for top-5 using this modified WLASL dataset. Our method, which does not require multi-modal data input, outperforms other state-of-the art approaches on the same modified WLASL dataset, demonstrating the importance of both attention to the start and end frames of signs and the use of bidirectional data streams in the GCNs for isolated sign recognition.
Carol Neidle, Augustine Opoku, and Dimitris Metaxas (2022) ASL Video Corpora & Sign Bank: Resources Available through the American Sign Language Linguistic Research Project (ASLLRP). arXiv:2201.07899 [cs.CL]1-20
https://doi.org/10.48550/arXiv.2201.07899BU Open Access: https://hdl.handle.net/2144/44189
The American Sign Language Linguistic Research Project (ASLLRP) provides Internet access to high-quality ASL video data, generally including front and side views and a close-up of the face. The manual and non-manual components of the signing have been linguistically annotated using SignStream®. The recently expanded video corpora can be browsed and searched through the Data Access Interface (DAI 2) we have designed; it is possible to carry out complex searches. The data from our corpora can also be downloaded; annotations are available in an XML export format. We have also developed the ASLLRP Sign Bank, which contains almost 6,000 sign entries for lexical signs, with distinct English-based glosses, with a total of 41,830 examples of lexical signs (in addition to about 300 gestures, over 1,000 fingerspelled signs, and 475 classifier examples). The Sign Bank is likewise accessible and searchable on the Internet; it can also be accessed from within SignStream® (software to facilitate linguistic annotation and analysis of visual language data) to make annotations more accurate and efficient. Here we describe the available resources. These data have been used for many types of research in linguistics and in computer-based sign language recognition from video; examples of such research are provided in the latter part of this article.
Sooyeon Lee, Abraham Glasser, Becca Dingman, Zhaoyang Xia, Dimitris Metaxas, Carol Neidle, and Matt Huenerfauth (2021) American Sign Language Video Anonymization to Support Online Participation of Deaf and Hard of Hearing Users. ASSETS 2021 (the 23rd International ACM SIGACCESS Conference on Computers and Accessibility). October 18-22, 2021. Available from https://dl.acm.org/doi/abs/10.1145/3441852.3471200 (with a video recording of the conference presentation).
BU Open Access (pre-publication version) : https://hdl.handle.net/2144/43545
Without a commonly accepted writing system for American Sign Language (ASL), Deaf or Hard of Hearing (DHH) ASL signers who wish to express opinions or ask questions online must post a video of their signing, if they prefer not to use written English, a language in which they may feel less proficient. Since the face conveys essential linguistic meaning, the face cannot simply be removed from the video in order to preserve anonymity. Thus, DHH ASL signers cannot easily discuss sensitive, personal, or controversial topics in their primary language, limiting engagement in online debate or inquiries about health or legal issues. We explored several recent attempts to address this problem through development of “face swap” technologies to automatically disguise the face in videos while preserving essential facial expressions and natural human appearance. We presented several prototypes to DHH ASL signers (N=16) and examined their interests in and requirements for such technology. After viewing transformed videos of other signers and of themselves, participants evaluated the understandability, naturalness of appearance, and degree of anonymity protection of these technologies. Our study revealed users’ perception of key trade-offs among these three dimensions, factors that contribute to each, and their views on transformation options enabled by this technology, for use in various contexts. Our findings guide future designers of this technology and inform selection of applications and design features.
Dimitris Metaxas and Carol Neidle, Technical Methods & Resources for American Sign Language (ASL). Chalearn Looking at People: Sign Language Recognition in the Wild Workshop at CVPR. June 25, 2021. https://chalearnlap.cvc.uab.cat/workshop/42/program/ Carol Neidle and Dimitris Metaxas, Linguistic Foundations for Computationally Efficient and Scalable Sign Recognition. Automatic Recognition and Analysis of American Sign Language, University of Chicago, IL. May 15, 2019.
We describe our general framework for linguistically-driven, computationally efficient, and scalable sign recognition, highlighting the ways in which known properties of linguistic structure and organization can constrain and enhance computer-based recognition. This talk also provides an overview of resources made available through the American Sign Language Linguistic Research Project (ASLLRP) for use in sign language recognition research: our Web-accessible, linguistically annotated, video corpora and Sign Bank, as well as our software annotation tool, SignStream®.
Dimitris Metaxas and Carol Neidle, Linguistically-Driven Machine Learning Methods for ASL Recognition. Automatic Recognition and Analysis of American Sign Language, University of Chicago, IL. May 15, 2019.
We present our machine learning methods that use linguistically motivated features from 3D upper body and face tracking within a neural network framework for signer-independent recognition of isolated signs and detection and identification of linguistically important information expressed non-manually. For isolated signs, based on a 350-sign vocabulary from the ASLLRP publicly shared, linguistically annotated, video corpora, Metaxas et al. (2018) achieved recognition accuracy of 93% for top-1 and 98% for top-5.
Dimitris Metaxas, Mark Dilsizian, and Carol Neidle, Linguistically-driven Framework for Computationally Efficient and Scalable Sign Recognition. LREC 2018, Miyagawa, Japan. May 2018.
BU Open Access: https://hdl.handle.net/2144/30048
We introduce a new general framework for sign recognition from monocular video using limited quantities of annotated data. The novelty of the hybrid framework we describe here is that we exploit state-of-the art learning methods while also incorporating features based on what we know about the linguistic composition of lexical signs. In particular, we analyze hand shape, orientation, location, and motion trajectories, and then use CRFs to combine this linguistically significant information for purposes of sign recognition. Our robust modeling and recognition of these sub-components of sign production allow an efficient parameterization of the sign recognition problem as compared with purely data-driven methods. This parameterization enables a scalable and extendable time-series learning approach that advances the state of the art in sign recognition, as shown by the results reported here for recognition of isolated, citation-form, lexical signs from American Sign Language (ASL).
Carol Neidle, Augustine Opoku, Gregory Dimitriadis, and Dimitris Metaxas, NEW Shared & Interconnected ASL Resources: SignStream® 3 Software; DAI 2 for Web Access to Linguistically Annotated Video Corpora; and a Sign Bank. 8th Workshop on the Representation and Processing of Sign Languages: Involving the Language Community (pp. 147-154). LREC 2018, Miyagawa, Japan. May 2018.
PosterBU Open Access: https://open.bu.edu/handle/2144/30047
2017 marked the release of a new version of SignStream® software, designed to facilitate linguistic analysis of ASL video. SignStream® provides an intuitive interface for labeling and time-aligning manual and non-manual components of the signing. Version 3 has many new features. For example, it enables representation of morpho phonological information, including display of handshapes. An expanding ASL video corpus, annotated through use of SignStream®, is shared publicly on the Web. This corpus (video plus annotations) is Web-accessible—browsable, searchable, and downloadable—thanks to a new, improved version of our Data Access Interface: DAI 2. DAI 2 also offers Web access to a brand new Sign Bank, containing about 10,000 examples of about 3,000 distinct signs, as produced by up to 9 different ASL signers. This Sign Bank is also directly accessible from within SignStream®, thereby boosting the efficiency and consistency of annotation; new items can also be added to the Sign Bank. Soon to be integrated into SignStream® 3 and DAI 2 are visualizations of computer-generated analyses of the video: graphical display of eyebrow height, eye aperture, and head position. These resources are publicly availablPe, for linguistic and computational research and for those who use or study ASL.
.
Link to self-playing PowerPoint shows SignStream® 3
Dropbox link: SignStream® 3
DAI 2 &
Sign BankDropbox link: DAI 2 and the Sign Bank
Dimitris Metaxas, Mark Dilsizian, and Carol Neidle, Scalable ASL Sign Recognition using Model-based Machine Learning and Linguistically Annotated Corpora. 8th Workshop on the Representation and Processing of Sign Languages: Involving the Language Community (pp. 127-132). LREC 2018, Miyagawa, Japan. May 2018.
BU Open Access: https://hdl.handle.net/2144/30049
We report on the high success rates of our new, scalable, computational approach for sign recognition from monocular video, exploiting linguistically annotated ASL datasets with multiple signers. We recognize signs using a hybrid framework combining state-of-the-art learning methods with features based on what is known about the linguistic composition of lexical signs. We model and recognize the sub-components of sign production, with attention to hand shape, orientation, location, motion trajectories, plus non-manual features, and we combine these within a CRF framework. The effect is to make the sign recognition problem robust, scalable, and feasible with relatively smaller datasets than are required for purely data-driven methods. From a 350-sign vocabulary of isolated, citation-form lexical signs from the American Sign Language Lexicon Video Dataset (ASLLVD), including both 1- and
2-handed signs, we achieve a top-1 accuracy of 93.3% and a top-5 accuracy of 97.9%. The high probability with which we can produce 5 sign candidates that contain the correct result opens the door to potential applications, as it is reasonable to provide a sign lookup functionality that offers the user 5 possible signs, in decreasing order of likelihood, with the user then asked to select the desired sign.
Carol Neidle, Language in the Visual-Gestural Modality: Linguistic and Computational Research Synergies. Keynote presentation, 2017. Johns Hopkins Center for Talented Youth: Family Academic Programs Science and Technology Series, Boston University, October 21, 2017.
Polina Yanovich, Carol Neidle, and Dimitris Metaxas, Detection of Major ASL Sign Types in Continuous Signing for ASL Recognition. LREC 2016, Portorož, Slovenia. May 25-27, 2016. http://www.lrec-conf.org/proceedings/lrec2016/pdf/714_Paper.pdf
BU Open Access: https://hdl.handle.net/2144/27492
In American Sign Language (ASL) as well as other signed languages, different classes of signs (e.g., lexical signs, fingerspelled signs, and classifier constructions) have different internal structural properties. Continuous sign recognition accuracy can be improved through use of distinct recognition strategies, as well as different training datasets, for each class of signs. For these strategies to be applied, continuous signing video needs to be segmented into parts corresponding to particular classes of signs. In this paper we present a multiple instance learning-based segmentation system that accurately labels 91.27% of the video frames of 500 continuous utterances (including 7 different subjects) from the publicly accessible NCSLGR corpus <http://secrets.rutgers.edu/dai/queryPages/> (Neidle and Vogler, 2012). The system uses novel feature descriptors derived from both motion and shape statistics of the regions of high local motion. The system does not require a hand tracker.
Mark Dilsizian, Zhiqiang Tang, Dimitris Metaxas, Matt Huenerfauth, and Carol Neidle, The Importance of 3D Motion Trajectories for Computer-based Sign Recognition. 7th Workshop on the Representation and Processing of Sign Languages: Corpus Mining. LREC 2016, Portorož, Slovenia. May 28, 2016.
BU Open Access: https://open.bu.edu/handle/2144/27494
Computer-based sign language recognition from video is a challenging problem because of the spatiotemporal complexities inherent in sign production and the variations within and across signers. However, linguistic information can help constrain sign recognition to make it a more feasible classification problem. We have previously explored recognition of linguistically significant 3D hand configurations, as start and end handshapes represent one major component of signs; others include hand orientation, place of articulation in space, and movement. Thus, although recognition of handshapes (on one or both hands) at the start and end of a sign is essential for sign identification, it is not sufficient. Analysis of hand and arm movement trajectories can provide additional information critical for sign identification. In order to test the discriminative potential of the hand motion analysis, we performed sign recognition based exclusively on hand trajectories while holding the handshape constant. To facilitate this evaluation, we captured a collection of videos involving signs with a constant handshape produced by multiple subjects; and we automatically annotated the 3D motion trajectories. 3D hand locations are normalized in accordance with invariant properties of ASL movements. We trained time-series learning-based models for different signs of constant handshape in our dataset using the normalized 3D motion trajectories. Results show signicant computer-based sign recognition accuracy across subjects and across a diverse set of signs. Our framework demonstrates the discriminative power and importance of 3D hand motion trajectories for sign recognition, given known handshapes.Hernisa Kacorri, Ali Raza Syed, Matt Huenerfauth, and Carol Neidle, Centroid-Based Exemplar Selection of ASL Non-Manual Expressions using Multidimensional Dynamic Time Warping and MPEG4 Features. 7th Workshop on the Representation and Processing of Sign Languages: Corpus Mining. LREC 2016, Portorož, Slovenia. May 28, 2016.
BU Open Access: https://hdl.handle.net/2144/27493
We investigate a method for selecting recordings of human face and head movements from a sign language corpus to serve as a basis for generating animations of novel sentences of American Sign Language (ASL). Drawing from a collection of recordings that have been categorized into various types of non-manual expressions (NMEs), we define a method for selecting an exemplar recording of a given type using a centroid-based selection procedure, using multivariate dynamic time warping (DTW) as the distance function. Through intra- and inter-signer methods of evaluation, we demonstrate the efficacy of this technique, and we note useful potential for the DTW visualizations generated in this study for linguistic researchers collecting and analyzing sign language corpora.Carol Neidle, Linguistic and Computational Research Synergies for the Study of American Sign Language. Linguistics Colloquium, Yale University, New Haven, CT. April 18, 2016.
The American Sign Language Linguistic Research Project (ASLLRP) has involved collaborations between linguists studying the structural properties of American Sign Language (ASL) and computer scientists interested in the challenging problems of sign language recognition from video and generation via signing avatars.
A centerpiece of several related projects has been the creation of expanding, Web-accessible, searchable, linguistically annotated, computationally analyzed video corpora. Included are high-quality synchronized video files showing linguistic productions by native users of the language from multiple angles along with a close-up view of the face. The data sets currently available include a collection of utterances and short narratives, as well as almost 10,000 examples of individual, citation-form ASL sign productions (corresponding to about 3,000 ASL signs, each produced by up to 6 different signers). The Web interface is undergoing enhancements to expand the search capabilities and to allow ready access to visualizations of the computational analyses. The annotation software (SignStream®3) is under development and will soon be released. The publicly available corpora will also soon include a large amount of recently annotated video data.
Domain knowledge related to the linguistic organization of ASL, in large part derived from these annotated corpora, has been incorporated into computational learning methods for detecting the linguistically significant elements of the videos, in particular, for recognition of specific non-manual expressions (i.e., movements of the head and upper body, and facial expressions) that convey essential grammatical information over phrasal domains, and for segmentation and identification of manual signs from continuous signing. The computer-generated analyses of the video also offer great potential for use in linguistic research. Furthermore, the linguistic and computer-based models of the non-manual components of ASL are being leveraged to improve the quality of ASL generation via avatars.
This talk will present an overview of the collaborative research, discuss some of the challenges in relation to the linguistic properties of language in the visual-gestural modality, and describe the shared data sets.
*The work presented here has resulted from collaborations including Rutgers (Dimitris Metaxas, et al.), Gallaudet (Ben Bahan, Christian Vogler), and Boston (Stan Sclaroff, Ashwin Thangali) Universities, as well as the Rochester Institute of Technology (Matt Huenerfauth). This work has also been partially funded by grants from the National Science Foundation.
Carol Neidle, Using linguistic modeling and linguistically annotated corpora for computer-based sign language recognition from video. Invited presentation at the ChaLearn Looking at People Workshop 2014, held in conjunction with ECCV 2014 at the Swiss Federal Institute of Technology (ETH) Zurich, Switzerland. September 6-7. 2014.
This talk will report on recent and ongoing collaborative, crossdisciplinary research on computer-based recognition of American Sign Language (ASL) from monocular video, with attention to both the manual and non-manual components.
New 3D tracking and computational learning methods have been employed, in conjunction with linguistic modeling and linguistically annotated video corpora, for the automated detection and identification of essential linguistic information expressed through head motion and facial expressions that extend over varying phrasal domains (in work with D. Metaxas, B. Liu, J. Liu, X. Peng, and others). This modeling is also being applied to computer-based sign language generation, to create more lingistically realistic signing avatars (in joint work with M. Huenerfauth).
In collaborative work with computer scientists at Boston University (S. Sclaroff, A. Thangali) and Rutgers University (D. Metaxas, M. Dilsizian, and others), various approaches have been taken to increase the accuracy of recognition of hand configurations (an essential parameter in the formation of manual signs). These approaches incorporate exploitation of statistics from our annotated American Sign Language Lexicon Video Data set (ASLLVD) — containing nearly 10,000 examples of isolated signs — that reflect linguistic constraints and dependencies between the start and end hand configurations within a given "lexical" sign, and between the hand configurations on the dominant and non-dominant hand in 2-handed signs.
The videos, linguistic annotations, as well as some of the results and data visualizations from the computational analyses, are being made publicly accessible through our Web interface (DAI: Data Access Interface; implementation by C. Vogler) that facilitates browsing, searching, viewing, and downloading subsets of the available data.
Carol Neidle, Jingjing Liu, Bo Liu, Xi Peng, Christian Vogler, and Dimitris Metaxas, Computer-based Tracking, Analysis, and Visualization of Linguistically Significant Nonmanual Events in American Sign Language (ASL). Presented at the 6th Workshop on Representation and Processing of Sign Languages: Beyond the Manual Channel. LREC 2014, Reykjavik, Iceland, May 31, 2014.
BU Open Access: https://hdl.handle.net/2144/31880.
<http://www.bu.edu/av/asllrp/carol/3-23-LREC-wkshop-submitted.pdf>
Workshop proceedings:
<http://www.lrec-conf.org/proceedings/lrec2014/workshops/LREC2014Workshop-SignLanguage%20Proceedings.pdf>Our linguistically annotated American Sign Language (ASL) corpora have formed a basis for research to automate detection by computer of essential linguistic information conveyed through facial expressions and head movements. We have tracked head position and facial deformations, and used computational learning to discern specific grammatical markings. Our ability to detect, identify, and temporally localize the occurrence of such markings in ASL videos has recently been improved by incorporation of (1) new techniques for deformable model-based 3D tracking of head position and facial expressions, which provide significantly better tracking accuracy and recover quickly from temporary loss of track due to occlusion; and (2) a computational learning approach incorporating 2-level Conditional Random Fields (CRFs), suited to the multi-scale spatio-temporal characteristics of the data, which analyses not only low-level appearance characteristics, but also the patterns that enable identification of significant gestural components, such as periodic head movements and raised or lowered eyebrows. Here we summarize our linguistically motivated computational approach and the results for detection and recognition of nonmanual grammatical markings; demonstrate our data visualizations, and discuss the relevance for linguistic research; and describe work underway to enable such visualizations to be produced over large corpora and shared publicly on the Web.
Bo Liu, Jingjing Liu, Xiang Yu, Dimitris Metaxas and Carol Neidle, 3D Face Tracking and Multi-Scale, Spatio-temporal Analysis of Linguistically Significant Facial Expressions and Head Positions in ASL. Presented at LREC 2014, Reykjavik, Iceland, May 30, 2014.
BU Open Access: https://hdl.handle.net/2144/31882
<http://www.lrec-conf.org/proceedings/lrec2014/pdf/370_Paper.pdf>
Essential grammatical information is conveyed in signed languages by clusters of events involving facial expressions and movements of the head and upper body. This poses a significant challenge for computer-based sign language recognition. Here, we present new methods for the recognition of nonmanual grammatical markers in American Sign Language (ASL) based on: (1) new 3D tracking methods for the estimation of 3D head pose and facial expressions to determine the relevant low-level features; (2) methods for higher-level analysis of component events (raised/lowered eyebrows, periodic head nods and head shakes) used in grammatical markings―with differentiation of temporal phases (onset, core, offset, where appropriate), analysis of their characteristic properties, and extraction of corresponding features; (3) a 2-level learning framework to combine low- and high-level features of differing spatio-temporal scales. This new approach achieves significantly better tracking and recognition results than our previous methods.
Mark Dilsizian, Polina Yanovich, Shu Wang, Carol Neidle and Dimitris Metaxas, A New Framework for Sign Language Recognition based on 3D Handshape Identification and Linguistic Modeling. Presented at LREC 2014, Reykjavik, Iceland, May 29, 2014.
BU Open Access: https://hdl.handle.net/2144/31881
<http://www.lrec-conf.org/proceedings/lrec2014/pdf/1138_Paper.pdf>
Current approaches to sign recognition by computer generally have at least some of the following limitations: they rely on laboratory conditions for sign production, are limited to a small vocabulary, rely on 2D modeling (and therefore cannot deal with occlusions and off-plane rotations), and/or achieve limited success. Here we propose a new framework that (1) provides a new tracking method less dependent than others on laboratory conditions and able to deal with variations in background and skin regions (such as the face, forearms, or other hands); (2) allows for identification of 3D hand configurations that are linguistically important in American Sign Language (ASL); and (3) incorporates statistical information reflecting linguistic constraints in sign production. For purposes of large-scale computer-based sign language recognition from video, the ability to distinguish hand configurations accurately is critical. Our current method estimates the 3D hand configuration to distinguish among 77 hand configurations linguistically relevant for ASL. Constraining the problem in this way makes recognition of 3D hand configuration more tractable and provides the information specifically needed for sign recognition. Further improvements are obtained by incorporation of statistical information about linguistic dependencies among handshapes within a sign derived from an annotated corpus of almost 10,000 sign tokens.
Carol Neidle, Two invited presentations at Syracuse University, Syracuse, NY,
April 22, 2014:
- American Sign Language (ASL) and its Standing in the Academy
A recent survey by the Modern Language Association (MLA) of foreign language enrollments in the United States showed a dramatic increase in American Sign Language (ASL) enrollment since 1990. By 2009 ASL ranked as the 4th most studied foreign language in the United States, behind Spanish, French, and German. American universities have, in increasing numbers, come to accept ASL in satisfaction of their foreign language requirements. In this presentation, I will discuss some of the considerations relevant to such policy decisions, focusing on the linguistic properties of ASL, but also touching upon its cultural context and literary art forms. The study of American Sign Language, in part through the large collection of video materials now accessible to students, expands their horizons. It provides a valuable perspective on the nature of human language and reveals rich cultural and literary traditions generally unfamiliar to those outside of the Deaf community. It has the added benefit of enabling communication with those in the US and parts of Canada who use ASL as their primary language; as well as with Deaf people from elsewhere who have also learned ASL.
- Crossdisciplinary Approaches to Sign Language Research: Video Corpora for Linguistic Analysis and Computer-based Recognition of American Sign Language (ASL)
Carol Neidle, The American Sign Language Linguistic Research Project. NSF Avatar and Robotics Signing Creatures Workshop, Gallaudet University, Washington, DC, November 15, 2013. Carol Neidle, Crossdisciplinary Approaches to American Sign Language Research: Linguistically Annotated Video Corpora for Linguistic Analysis and Computer-based Sign Language Recognition/Generation. CUNY Linguistics Colloquium, October 10, 2013.
After a brief introduction to the linguistic organization of American Sign Language (ASL), this talk presents an overview of collaborations between linguists and computer scientists aimed at advancing sign language linguistics and computer-based sign language recognition (and generation). Underpinning this research are expanding, linguistically annotated, video corpora containing multiple synchronized views of productions of native users of ASL. These materials are being shared publicly through a Web interface, currently under development, that facilitates browsing, searching, viewing, and downloading subsets of the data.
Two sub-projects are highlighted:
(1) Linguistic modeling used to enhance computer vision-based recognition of manual signs. Statistics emerging from an annotated corpus of about 10,000 citation-form sign productions by six native signers make it possible to leverage linguistic constraints to make sign recognition more robust.
(2) Recognition of grammatical information expressed through complex combinations of facial expressions and head gestures -- marking such things as topic/focus, distinct types of questions, negation, if/when clauses, relative clauses, etc. -- based on state-of-the-art face and head tracking combined with machine learning techniques. This modeling is also being applied to creation of more natural and linguistically realistic signing avatars. Furthermore, the ability to provide computer-generated graphs illustrating, for large data sets, changes in eyebrow height, eye aperture, and head position (e.g.) over time, in relation to the start and end points of the manual signs in the phrases with which non-manual gestures co-occur, opens up new possibilities for linguistic analysis of the nonmanual components of sign language grammar and for crossmodal comparisons.
The research reported here has resulted from collaborations with many people, including Stan Sclaroff and Ashwin Thangali (BU), Dimitris Metaxas, Mark Dilsizian, Bo Liu, and Jingjing Liu (Rutgers), Ben Bahan and Christian Vogler (Gallaudet), and Matt Huenerfauth (CUNY Queens College) and has been made possible by funding from the National Science Foundation.
Jingjing Liu, Bo Liu, Shaoting Zhang, Fei Yang, Peng Yang, Dimitris N. Metaxas and Carol Neidle, Recognizing Eyebrow and Periodic Head Gestures using CRFs for Non-Manual Grammatical Marker Detection in ASL. Presented at a Special Session on Sign Language, FG 2013: 10th IEEE International Conference on Automatic Face and Gesture Recognition, Shanghai, China, April 25, 2013.
Changes in eyebrow configuration, in combination with head gestures and other facial expressions, are used to signal essential grammatical information in signed languages. Motivated by the goal of improving the detection of non-manual grammatical markings in American Sign Language (ASL), we introduce a 2-level CRF method for recognition of the components of eyebrow and periodic head gestures, differentiating the linguistically significant domain (core) from transitional movements (which we refer to as the onset and offset). We use a robust face tracker and 3D warping to extract and combine the geometric and appearance features, as well as a feature selection method to further improve the recognition accuracy. For the second level of the CRFs, linguistic annotations were used as training for partitioning of the gestures, to separate the onset and offset. This partitioning is essential to recognition of the linguistically significant domains (in between). We then use the recognition of onset, core, and offset of these gestures together with the lower level features to detect non-manual grammatical markers in ASL.
http://doi.ieeecomputersociety.org/10.1109/FG.2013.6553781
http://www.computer.org/csdl/proceedings/fg/2013/5545/00/06553781.pdf
Bo Liu, Dimitrios Kosmopoulos, Mark Dilsizian, Peng Yang, Carol Neidle, and Dimitris Metaxas, Detection and Classification of Non-manual Grammatical Markers in American Sign Language (ASL). Poster presented at the 2nd Multimedia and Vision Meeting in the Greater New York Area, Columbia University, New York City, NY, June 15, 2012.
Carol Neidle and Christian Vogler, A New Web Interface to Facilitate Access to Corpora: Development of the ASLLRP Data Access Interface, 5th Workshop on the Representation and Processing of Sign Languages: Interactions between Corpus and Lexicon, LREC 2012, Istanbul, Turkey, May 27, 2012. <link to workshop proceedings>
BU Open Access: https://hdl.handle.net/2144/31886
A significant obstacle to broad utilization of corpora is the difficulty in gaining access to the specific subsets of data and annotations that may be relevant for particular types of research. With that in mind, we have developed a web-based Data Access Interface (DAI), to provide access to the expanding datasets of the American Sign Language Linguistic Research Project (ASLLRP). The DAI facilitates browsing the corpora, viewing videos and annotations, searching for phenomena of interest, and downloading selected materials from the website. The web interface, compared to providing videos and annotation files off-line, also greatly increases access by people that have no prior experience in working with linguistic annotation tools, and it opens the door to integrating the data with third-party applications on the desktop and in the mobile space. In this paper we give an overview of the available videos, annotations, and search functionality of the DAI, as well as plans for future enhancements. We also summarize best practices and key lessons learned that are crucial to the success of similar projects.
Carol Neidle, Ashwin Thangali and Stan Sclaroff, Challenges in Development of the American Sign Language Lexicon Video Dataset (ASLLVD) Corpus, 5th Workshop on the Representation and Processing of Sign Languages: Interactions between Corpus and Lexicon, LREC 2012, Istanbul, Turkey, May 27, 2012. <link to workshop proceedings>
BU Open Access: https://open.bu.edu/handle/2144/31899
The American Sign Language Lexicon Video Dataset (ASLLVD) consists of videos of >3,300 ASL signs in citation form, each produced by 1-6 native ASL signers, for a total of almost 9,800 tokens. This dataset, including multiple synchronized videos showing the signing from different angles, will be shared publicly once the linguistic annotations and verifications are complete. Linguistic annotations include gloss labels, sign start and end time codes, start and end handshape labels for both hands, morphological and articulatory classifications of sign type. For compound signs, the dataset includes annotations for each morpheme. To facilitate computer vision-based sign language recognition, the dataset also includes numeric ID labels for sign variants, video sequences in uncompressed-raw format, camera calibration sequences, and software for skin region extraction. We discuss here some of the challenges involved in the linguistic annotations and categorizations. We also report an example computer vision application that leverages the ASLLVD: the formulation employs a HandShapes Bayesian Network (HSBN), which models the transition probabilities between start and end handshapes in monomorphemic lexical signs. Further details and statistics for the ASLLVD dataset, as well as information about annotation conventions, are available from http://www.bu.edu/asllrp/lexicon.
Dimitris Metaxas, Bo Liu, Fei Yang, Peng Yang, Nicholas Michael, and Carol Neidle, Recognition of Nonmanual Markers in American Sign Language (ASL) Using Non-Parametric Adaptive 2D-3D Face Tracking, LREC 2012, Istanbul, Turkey, May 24, 2012. <link to LREC proceedings>
BU Open Access: https://hdl.handle.net/2144/31898
This paper addresses the problem of automatically recognizing linguistically significant nonmanual expressions in American Sign Language from video. We develop a fully automatic system
that is able to track facial expressions and head movements, and detect and recognize facial events continuously from video. The main contributions of the proposed framework are the following: (1) We have built a stochastic and adaptive ensemble of face trackers to address factors resulting in lost face track; (2) We combine 2D and 3D deformable face models to warp input frames, thus correcting for any variation in facial appearance resulting from changes in 3D head pose; (3) We use a combination of geometric features and texture features extracted from a canonical frontal representation. The proposed new framework makes it possible to detect grammatically significant nonmanual expressions from continuous signing and to differentiate successfully among linguistically significant expressions that involve subtle differences in appearance. We present results that are based on the use of a dataset containing 330 sentences from videos that were collected and linguistically annotated at Boston University.Zoya Gavrilova, Stan Sclaroff, Carol Neidle, and Sven Dickinson, Detecting Reduplication in Videos of American Sign Language, LREC 2012, Istanbul, Turkey, May 25, 2012. <link to LREC proceedings>
A framework is proposed for the detection of reduplication in digital videos of American Sign Language (ASL). In ASL, reduplication is used for a variety of linguistic purposes, including overt marking of plurality on nouns, aspectual inflection on verbs, and nominalization of verbal forms. Reduplication involves the repetition, often partial, of the articulation of a sign. In this paper, the apriori algorithm for mining frequent patterns in data streams is adapted for finding reduplication in videos of ASL. The proposed algorithm can account for varying weights on items in the apriori algorithm’s input sequence. In addition, the apriori algorithm is extended to allow for inexact matching of similar hand motion subsequences and to provide robustness to noise. The formulation is evaluated on 105 lexical signs produced by two native signers. To demonstrate the formulation, overall hand motion direction and magnitude are considered; however, the formulation should be amenable to combining these features with others, such as hand shape, orientation, and place of articulation.
Carol Neidle and Stan Sclaroff, A Demonstration System For Video-Based Sign Language Retrieval. Presented at the Rafik B. Hariri Institute for Computing and Computational Science & Engineering, Boston University, May 15, 2012. Carol Neidle, Conditional Constructions in ASL: Signs of Irrealis and Hypotheticality. Presented at the Institut Jean‐Nicod, CNRS, in Paris, France, April 4, 2012. Nicholas Michael, Peng Yang, Dimitris Metaxas, and Carol Neidle, A Framework for the Recognition of Nonmanual Markers in Segmented Sequences of American Sign Language, British Machine Vision Conference 2011, Dundee, Scotland, August 31, 2011. Ashwin Thangali, Joan P. Nash, Stan Sclaroff and Carol Neidle, Exploiting Phonological Constraints for Handshape Inference in ASL Video, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2011.
BU Open Access: https://open.bu.edu/handle/2144/11370
Handshape is a key linguistic component of signs, and thus, handshape recognition is essential to algorithms for sign language recognition and retrieval. In this work, linguistic constraints on the relationship between start and end handshapes are leveraged to improve handshape recognition accuracy. A Bayesian network formulation is proposed for learning and exploiting these constraints, while taking into consideration inter-signer variations in the production of particular handshapes. A Variational Bayes formulation is employed for supervised learning of the model parameters. A non-rigid image alignment algorithm, which yields improved robustness to variability in handshape appearance, is proposed for computing image observation likelihoods in the model. The resulting handshape inference algorithm is evaluated using a dataset of 1500 lexical signs in American Sign Language (ASL), where each lexical sign is produced by three native ASL signers.
Carol Neidle, with Joan Nash and Christian Vogler, Two Web-Accessible ASL Corpora. Sign language corpus workshop, Gallaudet University, Washington, DC, May 21, 2011. Haijing Wang, Alexandra Stefan, Sajjad Moradi, Vassilis Athitsos, Carol Neidle, and Farhad Kamangar, A System for Large Vocabulary Sign Search. International Workshop on Sign, Gesture, and Activity (SGA) 2010, in conjunction with ECCV 2010. September 11, 2010. Hersonissos, Heraklion, Crete, Greece.
A method is presented, that helps users look up the meaning of an unknown sign from American Sign Language (ASL). The user submits as a query a video of the unknown sign, and the system retrieves the most similar signs from a database of sign videos. The user then reviews the retrieved videos to identify the video displaying the sign of interest. Hands aredetected in a semi-automatic way: the system performs some hand detection and tracking, andthe user has the option to verify and correct the detected hand locations. Features are extractedbased on hand motion and hand appearance. Similarity between signs is measured bycombining dynamic time warping (DTW) scores, that are based on hand motion, with a simplesimilarity measure based on hand appearance. In user-independent experiments, with a system vocabulary of 1,113 signs, the correct sign was included in the top 10 matches for 78% of thetest queries.
Stan Sclaroff, Vassilis Athitsos, Carol Neidle, Joan Nash, Alexandra Stefan, Ashwin Thangali, Haijing Wang, and Quan Yuan, American Sign Language Lexicon Project: Video Corpus and Indexing/Retrieval Algorithms (poster). International Workshop on Computer Vision (IWCV), Vietri Sul Mare, Salerno, Italy. May 25-27, 2010.
Nicholas Michael, Carol Neidle, Dimitris Metaxas, Computer-based recognition of facial expressions in ASL: from face tracking to linguistic interpretation. 4th Workshop on the Representation and Processing of Sign Languages: Corpora and Sign Language Technologies, LREC 2010, May 22-23, 2010.
Most research in the field of sign language recognition has focused on the manual component of signing, despite the fact that there is critical grammatical information expressed through facial expressions and head gestures. We, therefore, propose a novel framework for robust tracking and analysis of nonmanual behaviors, with an application to sign language recognition. Our method uses computer vision techniques to track facial expressions and head movements from video, in order to recognize such linguistically significant expressions. The methods described here have relied crucially on the use of a linguistically annotated video corpus that is being developed, as the annotated video examples have served for training and testing our machine learning models. We apply our framework to continuous recognition of three classes of grammatical expressions, namely wh-questions, negative expressions, and topics.
Vassilis Athitsos, Carol Neidle, Stan Sclaroff, Joan Nash, Alexandra Stefan, Ashwin Thangali, Haijing Wang, and Quan Yuan, Large Lexicon Project: American Sign Language Video Corpus and Sign Language Indexing/Retrieval Algorithms. 4th Workshop on the Representation and Processing of Sign Languages: Corpora and Sign Language Technologies, LREC 2010, May 22-23, 2010.
When we encounter a word that we do not understand in a written language, we can look it up in a dictionary. However, looking up the meaning of an unknown sign in American Sign Language (ASL) is not nearly as straightforward. This paper describes progress in an ongoing project aiming to build a computer vision system that helps users look up the meaning of an unknown ASL sign. When a user encounters an unknown ASL sign, the user submits a video of that sign as a query to the system. The system evaluates the similarity between the query and video examples of all signs in the known lexicon, and presents the most similar signs to the user. The user can then look at the retrieved signs and determine if any of them matches the query sign.
An important part of the project is building a video database containing examples of a large number of signs. So far we have recorded at least two video examples for almost all of the 3,000 signs contained in the Gallaudet dictionary. Each video sequence is captured simultaneously from four different cameras, providing two frontal views, a side view, and a view zoomed in on the face of the signer. Our entire video dataset is publicly available on the Web.
Automatic computer vision-based evaluation of similarity between signs is a challenging task. In order to improve accuracy, we manually annotate the hand locations in each frame of each sign in the database. While this is a time-consuming process, this process incurs a one-time preprocessing cost that is invisible to the end-user of the system. At runtime, once the user has submitted the query video, the current version of the system asks the user to specify hand locations in the first frame, and then the system automatically tracks the location of the hands in the rest of the query video. The user can review and correct the hand location results. Every correction that the user makes on a specific frame is used by the system to further improve the hand location estimates in other frames.
Once hand locations have been estimated for the query video, the system evaluates the similarity between the query video and every sign video in the database. Similarity is measured using the Dynamic Time Warping (DTW) algorithm, a well-known algorithm for comparing time series. The performance of the system has been evaluated in experiments where 933 signs from 921 distinct sign classes are used as the dataset of known signs, and 193 signs are used as a test set. In those experiments, only a single frontal view was used for all test and training examples. For 68% of the test signs, the correct sign is included in the 20 most similar signs retrieved by the system. In ongoing work, we are manually annotating hand locations in the remainder of our collected videos, so as to gradually incorporate more signs into our system. We are also investigating better ways for measuring similarity between signs, and for making the system more automatic, reducing or eliminating the need for the user to manually provide information to the system about hand locations.
Nicholas Michael, Dimitris Metaxas, and Carol Neidle, Spatial and Temporal Pyramids for Grammatical Expression Recognition of American Sign Language. Eleventh International ACM SIGACCESS Conference on Computers and Accessibility. Philadelphia, PA, October 26-28, 2009. Carol Neidle, Nicholas Michael, Joan Nash, and Dimitris Metaxas, A Method for Recognition of Grammatically Significant Head Movements and Facial Expressions, Developed Through Use of a Linguistically Annotated Video Corpus. Workshop on Formal Approaches to Sign Languages, held as part of the 21st European Summer School in Logic, Language and Information, Bordeaux, France, July 20-31, 2009. Carol Neidle, Crossdisciplinary Corpus-Based ASL Research, 2008-2009 VL2 Presentation Series at Gallaudet University, Washington, DC, March 26, 2009, 4 pm.
This talk will (a) present information about a large, publicly available, linguistically annotated corpus, including high quality video files showing synchronized multiple views (with a close-up of the face) of Deaf native signers, and (b) discuss ways in which these data have been used in our linguistic and computer science collaborations. Projects include development of a sign look-up capability based on live or recorded video input, and recognition of various manual and non-manual properties of signing. This research has been supported by grants from the National Science Foundation (#CNS-0427988, #IIS-0705749).
V. Athitsos, C. Neidle, S. Sclaroff, J. Nash, A. Stefan, Q. Yuan, & A. Thangali, The American Sign Language Lexicon Video Dataset. First IEEE Workshop on CVPR for Human Communicative Behavior Analysis. Anchorage, Alaska, Monday June 28, 2008. Philippe Dreuw, Carol Neidle, Vassilis Athitsos, Stan Sclaroff, and Hermann Ney, Benchmark Databases for Video-Based Automatic Sign Language Recognition, the sixth International Conference on Language Resources and Evaluation (LREC). Morocco, May 2008.
BU Open Access: https://open.bu.edu/handle/2144/45763
Carol Neidle, Sign Language Research: Challenges for Sharing and Dissemination of Video Files and Linguistic Annotations, Preservation and Discovery in the Digital Age (ARL Directors' Meeting), Cambridge, MA, November 14-15, 2007.
Our linguistic research and computer science collaborations, supported by the National Science Foundation, rely on a large annotated corpus of sign language video data, which we wish to share with the linguistic and computer science research communities. The challenges for organizing and storing such data in ways that make it possible for others to identify the contents, search for data of interest to them, and then download the relevant materials will be addressed in this presentation.
G. Tsechpenakis, D. Metaxas, O. Hadjiliadis, and C. Neidle, Robust Online Change-point Detection in Video Sequences, 2nd IEEE Workshop on Vision for Human Computer Interaction (V4HCI) in conjunction with IEEE Conference on Computer Vision and Pattern Recognition (CVPR'06), New York, NY, June 2006. T. Castelli, M. Betke, and C. Neidle, Facial Feature Tracking and Occlusion Recovery in American Sign Language, Pattern Recognition in Information Systems (PRIS-2006) Workshop, Cyprus, May 23-24, 2006.
BU Open Access: https://open.bu.edu/handle/2144/1850
C. Neidle, The crossmodal study of human language and its importance to linguistic theory, Revolutions in Sign Language Studies: Linguistics, Literature, Literacy. Gallaudet University, March 22-24, 2006. G. Tsechpenakis, D. Metaxas, and C. Neidle, Learning-based dynamic coupling of discrete and continuous trackers, in Modeling People and Human Interaction workshop of ICCV 2005, Beijing, China, October 2005. W. He, X. Huang, G. Tsechpenakis, D. Metaxas, and C. Neidle, Discovery of Informative Unlabeled Data for Improved Learning, in Modeling People and Human Interaction workshop of ICCV 2005, Beijing, China, October 2005.
BU Open Access: https://open.bu.edu/handle/2144/45764
C. Neidle and R.G. Lee, Aspects of ASL syntax: CP and the left and right peripheries, guest lecture at the Linguistic Society of America Summer Institute, MIT, July 28, 2005. [See ASLLRP Report no. 12] C. Neidle and D. Metaxas, Linguistically-based computational methods for ASL recognition, SIGNA VOLANT, Sign Language Linguistics and the Application of Information Technology to Sign (SLL&IT), Milan, Italy, June 22-24, 2005. C. Neidle, Another look at some non-manual expressions of syntactic information in ASL, SIGNA VOLANT, Sign Language Linguistics and the Application of Information Technology to Sign (SLL&IT) , Milan, Italy, June 22-24, 2005. C. Neidle, participant in a panel discussion: How analysis shapes data; 2nd Conference of the International Society for Gesture Studies (ISGS), INTERACTING BODIES - CORPS EN INTERACTION, École normale supérieure Lettres et Sciences humaines, Lyon, France, June 15-18, 2005. D. Metaxas and C. Neidle, Linguistically-Based Computational Methods for ASL Recognition, Rutgers University Center for Cognitive Science (RuCCS) Colloquium, April 26, 2005 at 1 PM.
Signed languages involve simultaneous expression of different types of linguistic information through the manual and non-manual channels. In parallel with the signing of lexical material, primarily by the hands and arms, essential linguistic information is conveyed through facial expressions and gestures of the head and upper body, extending over varying, often phrasal, domains. We begin with an overview of the linguistic use of these channels in American Sign Language (ASL). Our linguistic studies have been accomplished in part through collection of video data from native ASL signers: high quality, synchronized views from multiple angles, including a close-up of the face. The annotations of the linguistically relevant components in the manual and non-manual channels have also been of critical importance in our research on computer-based ASL recognition. In this talk, we present and discuss recent advances in recognition of meaningful facial expressions made possible by the coupling of discrete and continuous tracking methods. The use of these methods to analyze hand motion is also enabling the discrimination of fingerspelled vs. non-fingerspelled signs. Given that these types of signs have very different internal linguistic structures, such discrimination is essential to recognition of manual signs.
This research has been supported by an NSF ITR grant to Rutgers University, Boston University, and Gallaudet University (D. Metaxas, C. Neidle and C. Vogler, PIs).
C. Neidle, Focus on the left and right peripheries in ASL. University of Toronto, February 4, 2005 at 3 PM.
Like other signed languages, ASL makes critical use of non-manual markings (gestures of the face and upper body) to express syntactic information. Quite a few different constructions, including 'if' and 'when' clauses, focused NPs, and 'relative clauses' (really correlatives), are characterized by very similar non-manual markings. Not concidentally, all of these phrases normally occur in a sentence-initial position and share some interesting semantic and syntactic commonalities. It is argued here that this position and grammatical marking are associated with Focus. The proposed analysis further provides an explanation (in terms of Rizzi's Relativized Minimality) for previously puzzling semantic and syntactic differences between wh-questions in which the wh-phrase does or does not undergo movement to the right periphery of the clause.
Considerations of focus also provide the key to understanding the apparent optionality of the non-manual realization of subject agreement. We argue that this non-manual marking, which suffices to license null subjects, in fact functions to mark focus. Thus, for example, the VP may or may not bear this focus marking -- which, when present, invariably includes an overt non-manual expression of subject agreement.
Thus, two puzzling cases of apparent optionality in the syntax of ASL are considered. In both cases, it is argued that focus is the relevant factor differentiating the variants.
C. Neidle, Language in another dimension: the syntax of American Sign Language (ASL). York University, DLLL, Ross S 562, February 3, 2005 at 4 PM.
Comparison of the way in which language is manifested in the visual-gestural and aural-oral modalities offers important insights into the nature of the human language faculty. This talk will provide an overview of the linguistic organization of ASL, focusing on the syntax of the language. In parallel with lexical items, which are articulated primarily by the hands, essential syntactic information is expressed through gestures of the face, head, and upper body. These extend over phrases (rather than individual lexical items) to convey information about, e.g., negation, question status and type, reference, subject and object agreement, mood, tense, aspect, definiteness, specificity, and information status (topic, focus). Video examples illustrating the constructions under discussion, as signed by native ASL signers, will be shown.
Because of the difficulties involved in studying language in the visual modality, the American Sign Language Linguistic Research Project has developed a computer application, SignStream, which has been invaluable in our own syntactic research and in collaborations with computer scientists interested in the problems of sign language recognition. Our annotated video data (multiple synchronized views of the signing, including a close-up of the face) may be of use to other researchers, as well. The presentation will include a brief demonstration of SignStream--a tool that can be applied more generally to the linguistic study of any kind of digital video data. It will conclude with mention of the collaborative research now underway on issues related to the problem of ASL recognition by computer.
C. Neidle, Reflexes of Focus in American Sign Language, Colloquium, Linguistics Department. University of Massachusetts, Amherst, November 12, 2004.
This presentation will begin with a brief overview of our syntactic research on American Sign Language, including mention of available annotated data sets (including high-quality video with multiple synchronized views of native signers) and collaboration with computer scientists interested in the problem of sign language recognition. Further information about the research to be reported on here, sponsored in part by grants from the National Science Foundation, is available from http://www.bu.edu/asllrp/.
Like other signed languages, ASL makes critical use of non-manual markings (gestures of the face and upper body) to express syntactic information. Quite a few different constructions, including 'if' and 'when' clauses, focused NPs, and 'relative clauses' (really correlatives), are characterized by very similar non-manual markings. Not coincidentally, all of these phrases normally occur in a sentence-initial position and share some interesting semantic and syntactic commonalities. It is argued here that this position and grammatical marking are associated with Focus. The proposed analysis further provides an explanation (in terms of Rizzi's Relativized Minimality) for previously puzzling semantic and syntactic differences between wh-questions in which the wh-phrase does or does not undergo movement to the right periphery of the clause.
Considerations of focus also provide the key to understanding the apparent optionality of the non-manual realization of subject agreement. We argue that this non-manual marking, which suffices to license null subjects, in fact functions to mark focus. Thus, for example, the VP may or may not bear this focus marking -- which, when present, includes an overt non-manual expression of subject agreement. Thus, two puzzling cases of apparent optionality in the syntax of ASL are considered. In both cases, it is argued that focus is the relevant factor differentiating the variants.
C. Neidle, Dimensions of linguistic research: Analysis of a signed language (plenary address). Australian Linguistic Society conference 2004, Sydney, Australia, July 13-15, 2004.
In signed languages, crucial information is expressed, in parallel, by manual signs and by facial expressions and movements of the head. Despite some interesting modality-dependent differences, the fundamental properties of spoken and signed languages are strikingly similar. Beginning with an overview of the linguistic organization of American Sign Language (ASL), this presentation will focus on several syntactic constructions in ASL that have been the subject of some controversy. Specifically, the nature and distribution of syntactic agreement and alternative structures for wh-questions will be discussed. In both cases, it will be argued that semantic and pragmatic factors (related to ‘focus’) differentiate seemingly optional syntactic variants.
Because of the difficulties of studying language in the visual modality, the American Sign Language Linguistic Research Project has developed a computer application, SignStream, which has been invaluable in our own syntactic research and in collaborations with computer scientists interested in the problems of sign language recognition. Our annotated video data (including synchronized views showing different perspectives of the signing and a close-up of the face) may be of use to other researchers, as well. The presentation will conclude with a brief demonstration of SignStream (a tool that can be applied more generally to the linguistic study of any kind of digital video) and information about the available annotated corpus of data collected from native users of American Sign Language.
C. Neidle and R.G. Lee, Unification, competition and optimality in signed languages: aspects of the syntax of American Sign Language (ASL). International Lexical Functional Grammar Conference. Christchurch, New Zealand, July 10-12, 2004.
[ABSTRACT]
C. Neidle, Resources for the study of visual language data: SignStream software for linguistic annotation and analysis of digital video and an annotated ASL corpus. International Lexical Functional Grammar Conference. Christchurch, New Zealand, July 10-12, 2004.
[ABSTRACT]
C. Neidle and R.G. Lee, Dimensions of the Linguistic Analysis of ASL: Challenges for Computer-Based Recognition. HCI Seminar Series, Computer Science and Artificial Intelligence Laboratory, MIT, June 9, 2004.
ASL and other signed languages have only recently been recognized to be full-fledged natural languages worthy of scientific study. These languages make use of complex articulations of the hands in parallel with linguistically significant facial gestures and head movements. Until recently, the lack of sophisticated tools for capture, annotation, retrieval, and analysis of the complex interplay of manual and non-manual elements has held back linguistic research. Thus, although there have been some fascinating discoveries in recent years, additional research on the linguistic structure of signed languages is badly needed. The relatively limited linguistic understanding of signed languages is, in turn, a hindrance for progress in computer-based sign language recognition. For these reasons, crossdisciplinary collaborations are needed in order to achieve advances in both domains.
This talk provides an overview of the nature of linguistic expression in the visual-spatial modality. It includes a demonstration of SignStream, an application developed by our research group for the annotation of video-based language data. SignStream has been used for creation of a substantial corpus of linguistically annotated data from native users of ASL, including high-quality synchronized video files showing the signing from multiple angles as well as a close-up view of the face. These video files and associated annotations, which have been used by many linguists and computer scientists (working separately and together), are being made publicly available.
C. Neidle and R.G. Lee, The SignStream Project: Available Resources and Future Directions. WORKSHOP ON THE REPRESENTATION AND PROCESSING OF SIGN LANGUAGES From SignWriting to Image Processing. Information techniques and their implications for teaching, documentation and communication. Workshop on the occasion of the 4th International Conference on Language Resources and Evaluation (LREC 2004). Lisbon, Portugal. May 30, 2004. C. Neidle and R.G. Lee, Syntactic agreement across language modalities: American Sign Language, Lisbon Workshop on Agreement, Universidade Nova de Lisboa, July 10-11, 2003.
R.G. Lee and C. Neidle, New developments in the annotation of gesture and sign language data: Advances in the SignStream project. The 5th International Workshop on Gesture and Sign Language based Human-Computer Interaction, Genova, Italy. April 15-17, 2003. Click here for pdf abstract.
C. Neidle and R.G. Lee, New developments in the annotation of gesture and sign language data: Advances in the SignStream project. University of Palermo, Italy. April 14, 2003 at 10.30.
C. Neidle and R.G. Lee, Questions and Conditionals in American Sign Language: Focusing on the left and right periphery, Università Milano-Bicocca, Italy. April 10, 2003 at 13.30.
Like other signed languages, ASL makes critical use of non-manual markings (gestures of the face and upper body) to express syntactic information. Quite a few different constructions, including 'if' clauses, 'when' clauses, focused NPs, and relative clauses, are characterized by very similar non-manual markings. Not concidentally, all of these phrases normally occur in a sentence-initial position and share some interesting semantic and syntactic commonalities. We argue here that this position and grammatical marking are associated with Focus. The proposed analysis further provides an explanation (in terms of Rizzi's Relativized Minimality) for previously puzzling semantic and syntactic differences between wh-questions in which the wh-phrase does or does not undergo movement to the right periphery of the clause.
C. Neidle, with Fran Conlin and Lana Cook. Focus and Wh Constructions in ASL. Harvard University GSAS Workshop Series on Comparative Syntax and Linguistic Theory. Cambridge, MA. May 17, 2002.
Wh-question constructions in American Sign Language (ASL) containing in situ wh phrases and moved wh phrases appearing at the right periphery of the clause will be compared. A syntactic account involving distinct projections for focus and wh phrases will be proposed. The differences in interpretation of the two constructions will be argued to follow from Relativized Minimality. Evidence in support of this analysis comes from (1) certain restrictions on the occurrence of wh-movement, and (2) the distribution of an indefinite focus particle in ASL.The findings to be discussed have emerged from joint work with Ben Bahan, Sarah Fish, and Paul Hagstrom, supported in part by grants from the National Science Foundation.
C. Neidle. Visual Analysis of Signed Language Data. Rutgers Center for Cognitive Science Colloquium. April 23, 2002.
Research on recognition and generation of signed languages and the gestural component of spoken languages has been held back by unavailability of large-scale linguistically annotated corpora of the kind that led to significant advances in the area of spoken language. A major obstacle to the production of such corpora has been the lack of computational tools to assist in efficient transcription and analysis of visual language data.This talk will begin with a discussion of a few of the interesting linguistic characteristics of language in the visual-gestural modality that pose a challenge for sign language recognition. Next, there will be a demonstration of SignStream, a computer program that we have designed to facilitate the linguistic analysis of visual language data. A substantial amount of high quality video data -- including multiple synchronized views of native users of American Sign Language (ASL) -- is being collected in our Center for Sign Language and Gesture Resources. These data, along with linguistic annotations produced through the use of SignStream, are being made publicly available in a variety of formats.
The second part of this talk will present some results of collaborative research now in progress between linguists and computer scientists in the development of computer vision algorithms to detect linguistically significant aspects of signing and gesture. The visual analysis of the sign language data will be discussed and relevant video examples will be presented.
The projects described here have been carried out in collaboration with Stan Sclaroff (Boston University) and Dimitris Metaxas (Rutgers), among other researchers, and they have been supported by grants from the National Science Foundation. Further information is available at http://www.bu.edu/asllrp/.
C. Neidle. American Sign Language: Linguistic Perspectives. Rutgers University Language and Linguistics Club. April 22, 2002.
A general overview of the linguistic organization of American Sign Language (ASL) will be presented. It will be argued that the fundamental linguistic properties of signed and spoken languages are the same, despite some interesting differences attributable to modality. SignStream, a computer program that we have designed to facilitate linguistic analysis of visual language data, will be demonstrated briefly. I will also report on ongoing collaborative research with computer scientists at Boston University (Stan Sclaroff) and at Rutgers (Dimitris Metaxas) and demonstrate some of our latest results.C. Neidle. Master Class for linguistics faculty: The Linguistics of American Sign Language. Rutgers University, April 22, 2002.
C. Neidle, Linguistic annotation and analysis of signed language using SignStream. Invited presentation at the IEEE* International Workshop on Cues in Communication ("Cues 2001") held in Conjunction with CVPR'2001. Kauai, Hawaii, USA. December 9, 2001.
C. Neidle, SignStream as a tool for linguistic annotation of signed language data. TalkBank Gesture Workshop, Carnegie Mellon University, Pittsburgh, PA, October 26-28, 2001.
C. Neidle, SignStream, un logiciel de base de données qui facilite l'encodage et l'analyse linguistique de données visuo-gestuelles. Transcription de la parole normale et pathologique - avec une session spéciale sur la transcription des langues des signes et du gestuel. l'Université de Tours, France. December 8 and 9, 2000.
C. Neidle and S. Sclaroff, SignStream: A tool for linguistic and computational research on visual-gestural language data. Third International Conference on Methods and Techniques in Behavioral Research. Nijmegen, The Netherlands, August 15-18, 2000.
Research on recognition and generation of signed languages and the gestural component of spoken languages has been held back by the unavailability of large-scale linguistically annotated corpora of the kind that led to significant advances in the area of spoken language. A major obstacle to the production of such corpora has been the lack of computational tools to assist in efficient analysis and transcription of visual language data.The first part of this talk will present SignStream™, a computer program that we have designed to facilitate the transcription and linguistic analysis of visual language data. SignStream provides a single computing environment for manipulating digital video and linking specific frame sequences to simultaneously occurring linguistic events encoded in a fine-grained multi-level transcription. Items from different fields are visually aligned on the screen to reflect their temporal relations, as illustrated in Figure 1.
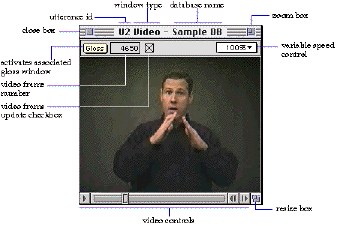
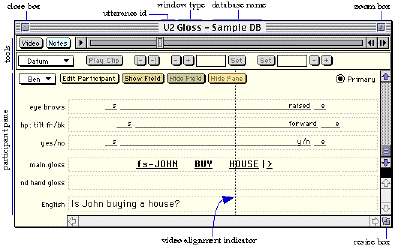
Figure 1. SignStream: video and gloss windows. We will describe the capabilities of the current release--which is distributed on a non-profit basis to educators and researchers--as well as additional features currently under development.Although SignStream may be of use for the analysis of any visual language data (including data from signed languages as well as the gestural component of spoken languages), we have been using the program primarily to analyze data from American Sign Language (ASL). This has resulted in a growing corpus of linguistically annotated ASL data (as signed by native signers). In the second part of this talk, we will discuss the ways in which the annotated corpus is being used in the development and refinement of computer vision algorithms to detect linguistically significant aspects of signing and gesture. This research is being conducted within the context of the National Center for Sign Language and Gesture Resources, which has established state-of-the-art digital video data collection facilities at Boston University and the University of Pennsylvania. Each lab is equipped with multiple synchronized digital cameras (see Figure 2) that capture different views of the subject (see Figure 3).

Figure 2. National Center for Sign Language and Gesture Resources:
data collection facility at Boston University.



Figure 3. Three views of a signer. The video data collected in this facility are being made publicly available in multiple video file formats, along with the associated linguistic annotations.The projects described here have been supported by grants from the National Science Foundation.
C. Neidle, SignStream, A tool for crosslinguistic analysis of signed languages. Seventh International Conference on Theoretical Issues in Sign Language Research (TISLR 2000). Amsterdam, The Netherlands. July 23-27, 2000.
D. MacLaughlin, Syntactic research on American Sign Language: The state of the art. Applied linguistics research seminar. Boston University, October 25, 1999.
C. Neidle and D. MacLaughlin, Language in another dimension: American Sign Language. Dartmouth College, Hanover, NH, October 22, 1999.
C. Neidle, D. MacLaughlin, and R.G. Lee, Language in the visual modality: Linguistic research and computational tools. University of Pennsylvania, May 7, 1999.
This talk focuses on issues surrounding linguistic research on signed languages and presents a demonstration of a computational tool to facilitate analysis of visual language data. We begin with an overview of the linguistic organization of American Sign Language. Next, we address particular problems associated with the collection, analysis, and dissemination of sign language data. We then present a demonstration of SignStream (http://www.bu.edu/asllrp/SignStream), a multimedia database tool currently under development as part of the American Sign Language Linguistic Research Project (http://www.bu.edu/asllrp).
SignStream-encoded language data will be made publicly available as part of a collaborative venture with the University of Pennsylvania to establish a National Center for Sign Language and Gesture Resources (U Penn: D. Metaxas, N. Badler, M. Liberman; Boston U: C. Neidle, S. Sclaroff).
C. Neidle, SignStream: A Multimedia Tool for Language Research. Poster presented at the National Science Foundation Human Computer Interaction Grantees' Workshop '99, Orlando, Florida, February 22, 1999.
C. Neidle and D. MacLaughlin, The Distribution of Functional Projections in ASL: Evidence from overt expressions of syntactic features. Workshop: The Mapping of functional projections. Università di Venezia and Venice International University, Isola di San Servolo, Venice, Italy, January 29, 1999.
To download a pdf version of the handout and digitized video examples, click here.
C. Neidle, R.G. Lee, D. MacLaughlin, B. Bahan, and J. Kegl, SignStream and the American Sign Language Linguistic Research Project. University of Stellenbosch, South Africa, February 19, 1997.
C. Neidle, J. Kegl, B. Bahan, D. MacLaughlin, and R. G. Lee, Non-manual Grammatical Marking as Evidence for Hierarchical Relations in American Sign Language. Symposium presented at the Fifth International Conference on Theoretical Issues in Sign Language Research, Montreal. September 21, 1996.
C. Neidle, J. Kegl, D. MacLaughlin, R. G. Lee, and B. Bahan, The Distribution of Non-Manual Correlates of Syntactic Features: Evidence for the Hierarchical Organization of ASL
B. Bahan, C. Neidle, D. MacLaughlin, J. Kegl, and R. G. Lee, Non-Manual Realization of Agreement in the Clause
D. MacLaughlin, C. Neidle, B. Bahan, J. Kegl, and R. G. Lee, Non-Manual Realization of Agreement in the Noun Phrase
C. Neidle, J. Kegl, D. MacLaughlin, B. Bahan, and R. G. Lee, Demonstration of SignStream™ as part of Technology Displays at the Fifth International Conference on Theoretical Issues in Sign Language Research, Montreal. September 20, 1996.
C. Neidle, J. Kegl, D. MacLaughlin, B. Bahan, R. G. Lee, J. Hoza, O. Foelsche, and D. Greenfield, SignStream™: A Multimedia Database Tool for Linguistic Analysis. Poster session and software demonstration presented at the Fifth International Conference on Theoretical Issues in Sign Language Research, Montreal. September 19, 1996.
D. MacLaughlin, C. Neidle, B. Bahan, and J. Kegl, SignStream: A Multimedia Database for Sign Language Research. Talk and demonstration presented at the Human Movement Coding Workshop at City University, London, England, May 29, 1996.
D. MacLaughlin, C. Neidle, B. Bahan, and J. Kegl, The SignStream Project. Talk and demonstration presented at the University of Durham, England, May 28, 1996.
B. Bahan, C. Neidle, D. MacLaughlin, and J. Kegl, Non-Manual Realization of Agreement in American Sign Language. Talk presented at the University of Durham, England, May 27, 1996.
C. Neidle, D. MacLaughlin, B. Bahan, and J. Kegl, Non-Manual Correlates of Syntactic Agreement in American Sign Language. Talk presented at the University of Iceland, Reykjavik, May 23, 1996.
B. Bahan, J. Kegl, and C. Neidle, Introduction to Syntax for Sign Language Teachers; and The Spread of Grammatical Facial Expressions and Evidence of the Structure of Sentences in ASL. New York Statewide Conference for Teachers of American Sign Language. June 4, 1994.
C. Neidle, D. MacLaughlin, J. Kegl and B. Bahan, SignStream: A Multimedia Database for Sign Language Research. Talk presented at the University of Iceland, Reykjavik, May 22, 1996.
B. Bahan, ASL Literary Traditions. Talk presented at the University of Virginia, Charlottesville, April 12, 1996.
J. Kegl, B. Bahan, O. Foelsche, David Greenfield, J. Hoza, D. MacLaughlin, and C. Neidle, SignStream: A Multimedia Tool for Language Analysis. Talk presented at the Conference on Gestures Compared Cross-Linguistically, 1995 Linguistic Institute, University of New Mexico, Albuquerque, NM, July 10, 1995.
J. Kegl, B. Bahan, D. MacLaughlin, and C. Neidle, Overview of Arguments about Rightward Movement in ASL. Talk presented in the course on the Linguistic Structure of American Sign Language at the 1995 Linguistic Institute, University of New Mexico, Albuquerque, NM, July 11, 1995.
C. Neidle, D. MacLaughlin, J. Kegl, B. Bahan, and D. Aarons, Overt Realization of Syntactic Features in American Sign Language. Syntax Seminar, University of Trondheim, Trondheim, Norway, May 30, 1995.
B. Bahan, J. Kegl, D. MacLaughlin, and C. Neidle, Convergent Evidence for the Structure of Determiner Phrases in American Sign Language. Formal Linguistics Society of Mid-America, Bloomington, IN, May 19-21, 1995.
J. Shepard-Kegl, C. Neidle, and J. Kegl, Legal Ramifications of an Incorrect Analysis of Tense in ASL. American Association for Applied Linguistics, Baltimore, MD, March 8, 1994.
C. Neidle and J. Kegl, The Architecture of Functional Categories in American Sign Language. Syracuse University Linguistics Colloquium, Syracuse, NY, December 10, 1993.
D. Aarons, B. Bahan, J. Kegl, and C. Neidle, Tense and Agreement in American Sign Language. Fourth International Conference on Theoretical Issues in Sign Language Research, University of California, San Diego, August 5, 1992.
D. Aarons, J. Kegl, and C. Neidle, Subjects and Agreement in American Sign Language. Fifth International Symposium on Sign Language Research, Salamanca, Spain, May 26, 1992.
{kind=link}